



Quick takeaways
Memory poisoning is when bad inputs get written into an agent's long-term memory and later get recalled as if they were true. Once in, they are hard to remove and hard to debug.
The common cases are accidental: a sarcastic comment stored as a preference, a model hallucination written back as a fact, one user's bad data leaking into a shared scope.
Naive vector memory has no defense, because it tracks similarity, not trust. There is no source, no scope, no confidence, no decay.
Mem0 stores memories as typed objects with that metadata, so you can filter agent-generated facts out of safety-sensitive flows, keep preferences private per user, and decay stale entries.
If you are already writing model output back into memory, you have this problem now. The example shows how to use add() and search() calls and run them with a free API key from app.mem0.ai.
What is memory poisoning?
Production AI agents do not just process prompts; they accumulate memory. Over time, that memory becomes more important than any single input. If it drifts, the agent drifts. If it is poisoned, the agent becomes untrustworthy.
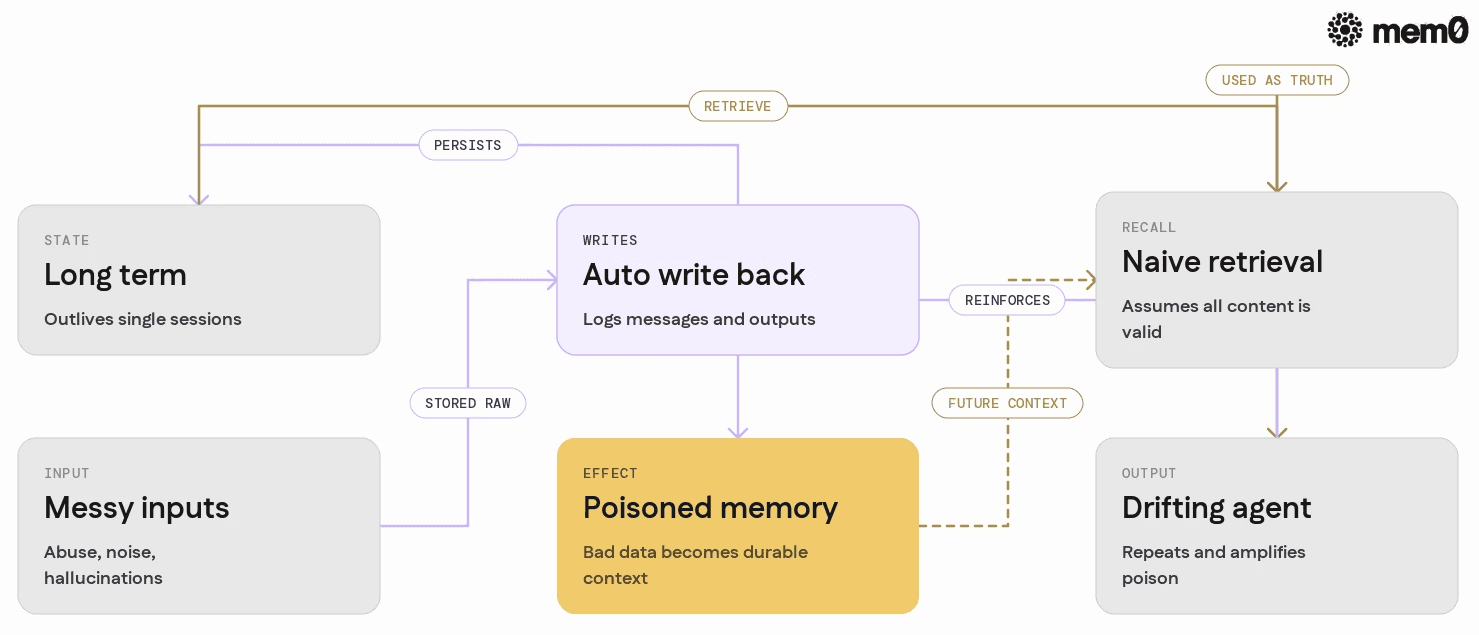
The problem is a combination of three properties:
Long-term state that outlives a single session
Automatic write-back from model outputs or raw user messages
Later recall that assumes stored content is valid context
For production agents, this creates specific failure cases:
A support bot internalizes incorrect product information from a user rant, then repeats it to others.
A research helper stores speculative or hallucinated facts as permanent knowledge.
A trading assistant learns a user's impulsive decisions as a preferred strategy, then recommends them later.
A multi-user system lets one account poison shared facts for everyone.
Memory is powerful because it persists context. Poisoning is dangerous for the same reason. Without constraints, anything can become part of the agent's enduring worldview.
Common memory patterns and where they break
Many agents start with simple memory patterns:
Raw transcript storage: Every message goes into a log, and retrieval pulls the most recent k messages.
Summarized memory: A background process compresses conversations into summary documents.
Vector similarity memory: Messages or summaries are embedded and stored in a vector database. Retrieval returns the nearest neighbors to the current query.
These patterns are attractive because they are easy to build. They are also where memory poisoning starts.
Key weaknesses:
No trust dimension, only similarity
No control over who can influence which memories
No concept of recency decay or confidence updates
No feedback loop from downstream signals like user corrections
In practice, this means:
A single adversarial or noisy session can introduce long-lived bad memories.
Rare but high-impact events stay forever, while better data later does not override them.
The agent cannot differentiate a user joke from a serious preference.
A model hallucination written back to memory becomes a self-reinforcing "fact".
The rest of this post focuses on these failure modes as types of memory poisoning.
Types of memory poisoning in AI agents
Even in well-intentioned systems, poisoning patterns appear naturally. A few common ones:
1. User-level preference poisoning: The agent learns from a user's behavior and language patterns. If the user has a bad habit or is in a transient state, the agent may overfit to that behavior. A user who vents late at night gets read as someone who "loves" drastic solutions. A user who jokingly says "I always want the riskiest trade possible" gets that stored as a standing preference.
2. Shared knowledge poisoning: In multi-user systems, one user's input can influence others if there is any shared memory layer. One annotator's incorrect labeling style gets normalized and leaks into suggestions for everyone. A single team member adds wrong instructions that the agent later recommends broadly.
3. System prompt and tool poisoning: Tools and system prompts can be treated as a form of memory. An agent that can suggest new tools and descriptions may later use its own unvetted tools. A summarizer that compresses a policy document incorrectly leaves future flows relying on the bad summary instead of the source.
4. Hallucination feedback loops: If generated content is written back to memory without checks, hallucinations become persistent. A research assistant stores speculative answers as notes, then retrieves and reinforces them later. A coding agent writes an imagined API into memory, then calls it when generating new code.
5. Adversarial poisoning: Some users will try to manipulate an agent through its memory. Prompt-injection instructions get stored and later retrieved. Coordinated users repeatedly assert that a target entity is unsafe, pushing the agent to treat it as untrustworthy.
All of these exist even before classic adversarial ML attacks against embeddings. They arise from the interaction between long-lived state, automatic writes, and naive retrieval.
👉 Want to see the difference structure makes? Grab a free Mem0 API key at app.mem0.ai and run the example below against your own agent's memory.
How Mem0 structures memory to reduce poisoning
Mem0 is an open-source memory layer that treats memories as first-class objects, not just chunks of text. Each memory has fields that are meaningful for control and safety.
At a high level, Mem0:
Extracts candidate memories from interactions, using LLM-guided extraction.
Stores them with metadata such as user_id, type, source, and timestamps.
Scores and updates memories over time based on use and corrections.
Exposes retrieval APIs that can filter and rank by metadata and policies.
A simplified conceptual schema:
id: memory identifieruser_id: which user this memory belongs to (optional for global memories)type: fact, preference, identity, task, feedback, etc.content: natural language description of the memorysource: human, agent, tool, systemscore: a numeric confidence or utility scorecreated_at,updated_at: timestampstags: arbitrary labels for application logic
This structure allows policies like:
Trust human feedback above self-generated content.
Keep user preferences private by default.
Downweight or expire memories with conflict signals.
Restrict retrieval to safe types for certain tools.
Mem0 does not automatically make an agent safe, but it provides the primitives needed to implement guardrails against memory poisoning.
Comparing naive memory vs structured memory with Mem0
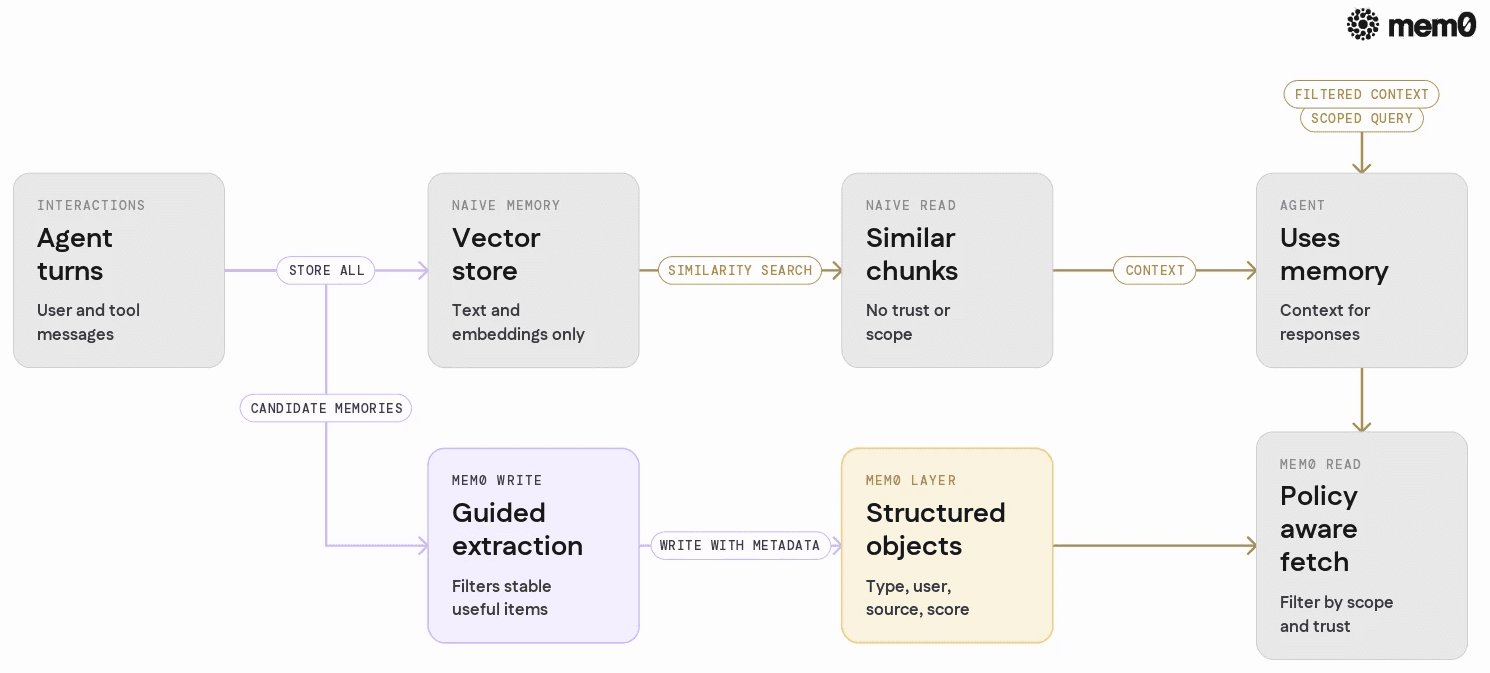
The following table summarizes differences relevant to poisoning:
Dimension | Naive vector store memory | Structured memory with Mem0 |
|---|---|---|
Data model | Text + embedding | Memory objects with type, source, user, score |
Write policy | Often "store everything" | LLM-guided extraction and app-level filters |
Trust / confidence | Implicit, not tracked | Explicit score and update rules |
User scoping | Often global or per-index | Per-user, per-group, or global scopes |
Conflict handling | Manual ad hoc cleanup | Signals for update, merge, or decay |
Retrieval filters | Similarity and maybe metadata | Rich filters on type, source, score, user, tags |
Safety integration | External and disconnected | Moderation hooks before write and before read |
Hallucination controls | Hard to distinguish source | Can exclude source="agent" facts from certain flows |
This structure is what enables principled responses to poisoning rather than one-off patches.
Integrating Mem0
The following example shows a minimal integration pattern using Mem0 in a conversational agent. The focus is on how to write and read memory safely, not on the full agent architecture.
👉Wanna give it a try? Get a Mem0 API Key and try it yourself.
First, install the Mem0 Python client:
A simple agent loop with Mem0:
This example demonstrates three anti-poisoning moves:
Retrieval scoped by
user_idthroughfilters, so one user cannot poison another's memory.A separate extraction step that decides what belongs in long-term memory, instead of storing every raw message.
A
sourcetag on every write, so later logic can prefer human-only memories over mixed or agent-generated ones.
⭐️ Try this yourself: drop in your own API key, run the loop, and feed it a sarcastic "I love risky trades" line. Watch what the extractor stores, then add a
source="agent"filter to your retrieval and see the difference in what comes back. It takes about two minutes on the free tier. Get your key.
In a production system, this pattern extends with scoring, moderation, and conflict handling, covered next.
Applying Mem0 patterns to reduce poisoning
Mem0's API and data model support several concrete patterns that help mitigate memory poisoning in practice.
1. Separate preference and fact memories: Preferences are user-specific and subjective. Facts should be globally consistent, or at least locally consistent within a domain. Label preference memories with type="preference" and a user_id, and domain facts with type="fact" and a broader scope or tag. Then retrieve only preferences for personalization tasks, only facts for reasoning that should not be biased by mood or transient statements, and apply different decay or conflict policies to each.
2. Track source and trust level: Not all memories should influence an agent equally. Use metadata["source"] to differentiate human, agent, tool, system, or composites. Assign higher initial scores to human statements and lower scores to agent-generated content. For safety-sensitive flows, filter out source="agent" facts to avoid hallucination feedback loops.
3. Use feedback to adjust memory scores: User corrections are valuable anti-poisoning signals. A user saying "that is wrong, I do not like that" should reduce the weight of related memories. Capture explicit corrections as new memories with type="feedback" linked to the original, then lower the referenced memory's score or mark it deprecated, and prefer higher-scored memories when resolving conflicts.
4. Apply moderation and filters at write-time: Rather than only moderating at inference time, run user and agent messages through safety classifiers before writing. Prevent storage of content that is clearly toxic, contains disallowed instructions, or exposes sensitive PII. Alternatively, store it but tag it and exclude it from default retrieval. Mem0's memory objects carry these moderation tags, which simplifies retrieval filters.
5. Decay or archive stale and low-value memories: Not all poisoning is malicious. Old and obsolete information can act as a mild poison if it dominates recall. Implement time-based decay of memory scores so infrequently used items fade, periodically archive or compress stale memories, and prioritize recent and frequently retrieved memories for most flows. Mem0's timestamps and scores make such policies easier to implement.
Limitations
Even with structured memory and policies, memory poisoning cannot be eliminated entirely. Important limitations include:
Model obedience to bad context: If poisoned content is retrieved and prompts are not crafted carefully, the model may still follow harmful instructions. A memory layer helps with filtering, but prompt design and tool constraints remain essential.
Ambiguous user intent: Sarcasm, jokes, and transient emotions are hard to distinguish from stable preferences. Even sophisticated extraction may misclassify them, and over-fitting is still possible.
Cross-domain generalization: A memory that is harmless in one domain may become harmful when applied elsewhere. A "take more risks" preference in entertainment recommendations is not safe for financial advice, and domain-aware routing is required.
Adversarial coordination: Coordinated poisoning attempts across multiple accounts are hard to detect from memory data alone. Additional anomaly detection and rate limiting are needed.
Tool and system layer interactions: Even if user-facing memory is clean, tools and system prompts can still introduce biases. The memory layer cannot control parts of the stack that do not pass through it.
Mem0 provides structure and control hooks, but effective defenses still require careful application-specific logic, monitoring, and testing.
Frequently Asked Questions
Q. What is memory poisoning in AI agents?
Memory poisoning is when incorrect, adversarial, or irrelevant information gets stored in an agent’s long‑term memory and later influences its behavior. It can arise from malicious users, model hallucinations, or simply accidental misuse of memory.
Q. How does Mem0 help reduce memory poisoning compared to a basic vector store?
Mem0 treats each memory as a typed object with metadata such as user, source, and score rather than just text with an embedding. This structure enables fine‑grained filters, trust policies, and update rules that limit how bad inputs are stored and retrieved.
Q. When should an agent write new information into Mem0?
Agents should write only information that is likely to be stable and useful over time, such as preferences, recurring facts, and confirmed corrections. Using an LLM‑based extraction step and moderation checks before writing helps avoid storing noisy or harmful content.
Q. Can Mem0 prevent all adversarial memory attacks?
No, Mem0 cannot guarantee complete protection against adversarial users or coordinated attacks. It provides the primitives to scope memories, track provenance, and apply policies, but application developers still need to design prompts, tools, and monitoring around those primitives.
Q. How should multi‑user agents use Mem0 safely?
Multi‑user agents should store user‑specific memories with a user_id and restrict retrieval to that scope by default. Shared or global memories should be reviewed more carefully, and applications can require higher trust or explicit curation before promoting data to shared scope.
Q. Why not let the LLM manage memory internally without an external layer?
LLMs can simulate memory in a single context window, but they cannot maintain structured, long‑lived state across sessions on their own. An external memory layer like Mem0 makes state transparent, queryable, and controllable, which is essential for debugging and defending against poisoning.
Further Reading
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or
Self-host mem0 from our open-source GitHub repository.
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

