



Large language models from Google and other providers are increasingly used as the core of production chatbots and agents. These systems appear to remember user preferences, previous chats, and task state. In practice, that "memory" is assembled from multiple layers, each with different guarantees and failure modes.
Understanding how memory really works in Google-style AI chatbots is critical for AI engineers. It affects safety, personalization, evaluation, and costs. It also determines how portable an agent is across models and clouds.
This article describes how memory behaves in the Google AI ecosystem, why the core memory problem is not solved by model internals, and how an external memory layer like Mem0 fits into production architectures.
💡If you are new to Mem0, check out our quickstart to add memory
to any agent in a few lines of code.
What memory means in LLM-based agents
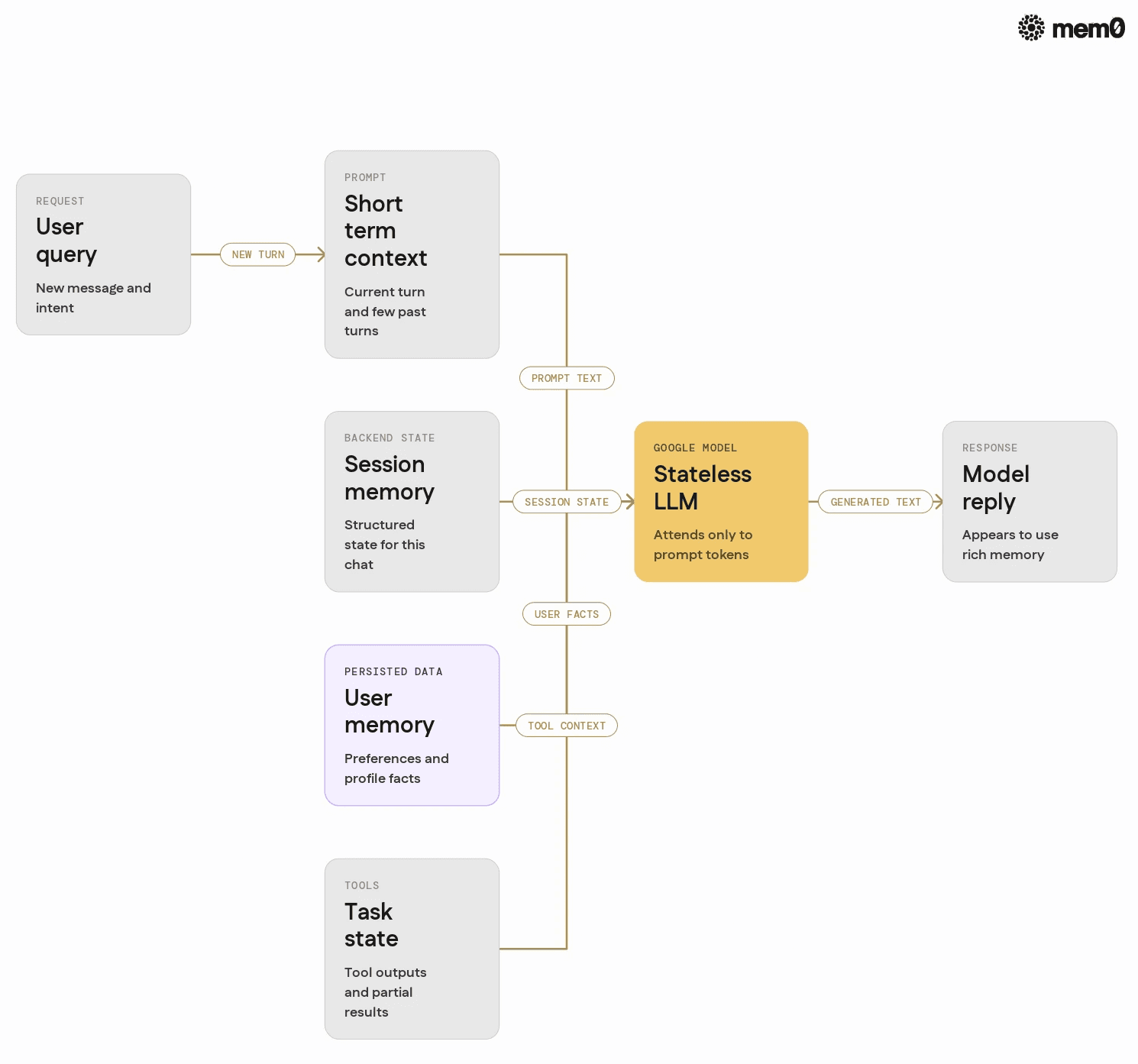
When people talk about "memory" in chatbots or agents, they usually mean at least four different things:
Short-term conversational context: Tokens sent to the model in the current request, which the model can attend to directly.
Ephemeral session memory: What the backend keeps for the current session, for example, the last N turns or a structured state object.
Persistent user memory: Facts about a user or tenant stored beyond a session, for example, preferences, profile data, recurring tasks.
Task and tool state: Intermediate results and tool outputs, for example, search results, file summaries, or database query outcomes.
Google AI models, like other LLMs, only "remember" what is in the prompt. They do not retain information between API calls. Any sensation of longer-term memory comes from how the application stores and re-injects data into prompts.
The core memory problem for production agents is therefore not training the model. It is designing and operating a memory system that survives across calls, users, and models, while remaining controllable and auditable.
How Google AI chatbots handle context within a session
Within a single interaction, Google AI models rely on the prompt and context window. Several patterns are common:
Chat history concatenation: The backend concatenates previous user and assistant turns, then sends them in each
contentsarray for Gemini or other Google models.Summarized history: Older turns are summarized into a shorter system or assistant message. This trades detail for token efficiency.
Context stuffing with tools: Results from tools like Google Search, Drive, or other APIs are added as extra messages in the prompt.
For example, in a simplified pseudo-request to a chat model:
The apparent "memory" is just the fact that the entire previous conversation is still in the prompt. If the history is truncated or summarized poorly, the model "forgets."
This approach works up to the context limit. Beyond that, engineers need strategies such as retrieval or external state.
Where longer-term memory usually lives in Google-style agents
Production chatbots built on Google AI APIs generally implement longer-term memory outside the model. Common storage patterns include:
Application databases: User profiles, preferences, interaction logs in Postgres, Firestore, or similar. The application queries these and injects results into prompts.
Vector stores: Indexed embeddings of past messages, tickets, documents, or events. A retrieval step selects relevant items for the current query.
Search indices: Full-text or hybrid search systems that surface relevant content, again used to augment the prompt.
Custom state stores: Key-value or document stores whose records encode task state, workflow stage, or other structured memory.
This is also how Google’s own products tend to act. Persisted state and memory live in separate infrastructure. The application is responsible for deciding what to store, how to query it, and what to inject.
From an engineering perspective, this means every agent needs a memory architecture, not just API calls.
The limits of implicit and emergent memory
LLMs exhibit some emergent "memory" behavior, but it is not the same as application memory.
Training data as memory
Models can answer questions about facts seen during training. That is not user-specific memory. It is a general prior. It cannot know that a specific tenant prefers CSV over XLSX unless the application feeds that information in the prompt.
Context window as memory
Models can only attend to tokens in their context window. Once a chat grows large, older content must be dropped or summarized. This introduces several limits:
Important details can be lost during summarization.
Relevant earlier facts might not be retrieved.
Context packing becomes complex and brittle.
Implicit pattern memory
A model can infer patterns within a single prompt, such as "the user tends to ask about product pricing." This inference disappears as soon as the context that carries it is dropped.
These limits mean that "just send more history" is not a viable long-term strategy for production agents that must operate across sessions and channels.
Comparing memory approaches in Google AI agents
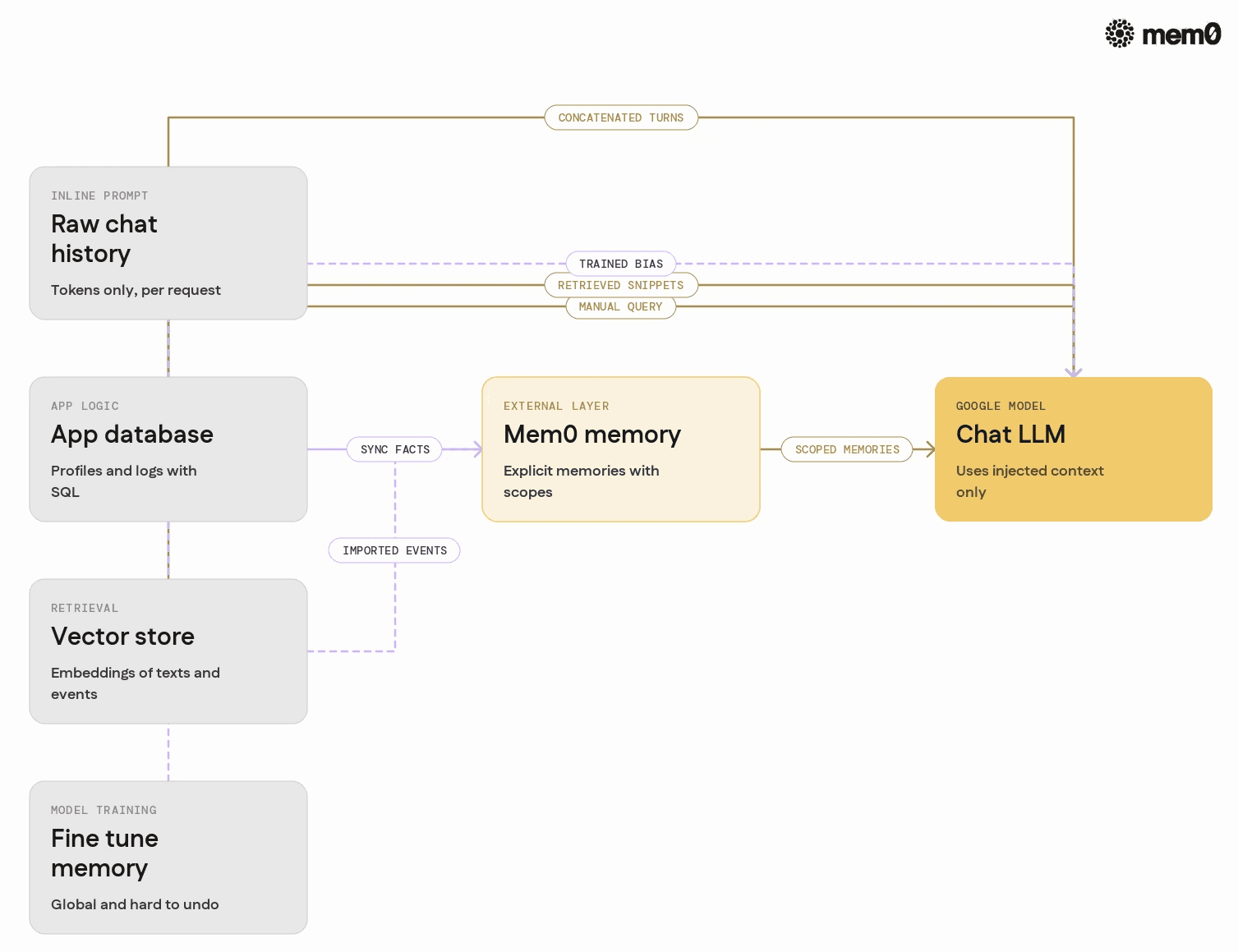
The table below compares common memory patterns used with Google AI and similar models, along with an external memory layer such as Mem0.
Memory approach | Scope | Persistence | Control & auditability | Typical issues |
|---|---|---|---|---|
Raw chat history in prompt | Single session | No, per request | Low, unstructured text | Context limit, cost, summarization complexity |
App DB with manual queries | User or tenant | Yes, app-managed | High, structured schemas | Custom logic per agent, brittle prompt glue |
Generic vector store | Documents or messages | Yes, configurable | Medium, embedding dependent | Over/under recall, schema drift, ranking issues |
In-model training / fine-tune | Global, all users | Yes, model-level | Low, hard to reverse or segment | Privacy risk, slow iteration, vendor lock-in |
External memory layer (Mem0) | User, agent, tasks | Yes, memory-level | High, explicit memory objects | Requires integration and design choices |
The last row is where Mem0 fits. It sits between the raw chat history and the application DB, providing a purpose-built, explicit memory layer instead of ad hoc glue code.
What Mem0 is in the context of Google AI agents
Mem0 is an open-source memory layer designed for LLMs and AI agents. In a Google AI-centric stack, Mem0 plays three roles:
Structured memory extraction: Mem0 watches interactions and extracts salient, atomic memories, for example, "user prefers weekly summaries on Monday" or "project Alpha uses the North America region."
Persistent memory store: These memories are stored with identities, scopes, timestamps, and metadata. They survive across sessions and can be queried by user, agent, or tenant.
Context injection for any model: When a new request arrives, Mem0 retrieves relevant memories, then feeds them into the prompt for the chosen model, including Google AI models. It is model-agnostic and can be used with multiple providers.
This creates a clear separation of concerns:
The LLM focuses on reasoning, generation, and tool use.
Mem0 focuses on what to remember, how long to keep it, and how to surface it.
The application focuses on business logic and orchestration.
Because Mem0 is external, memory is portable across providers. An agent that uses Google AI today can switch to another model tomorrow without losing user memory.
How Mem0 integrates with Google AI chatbots
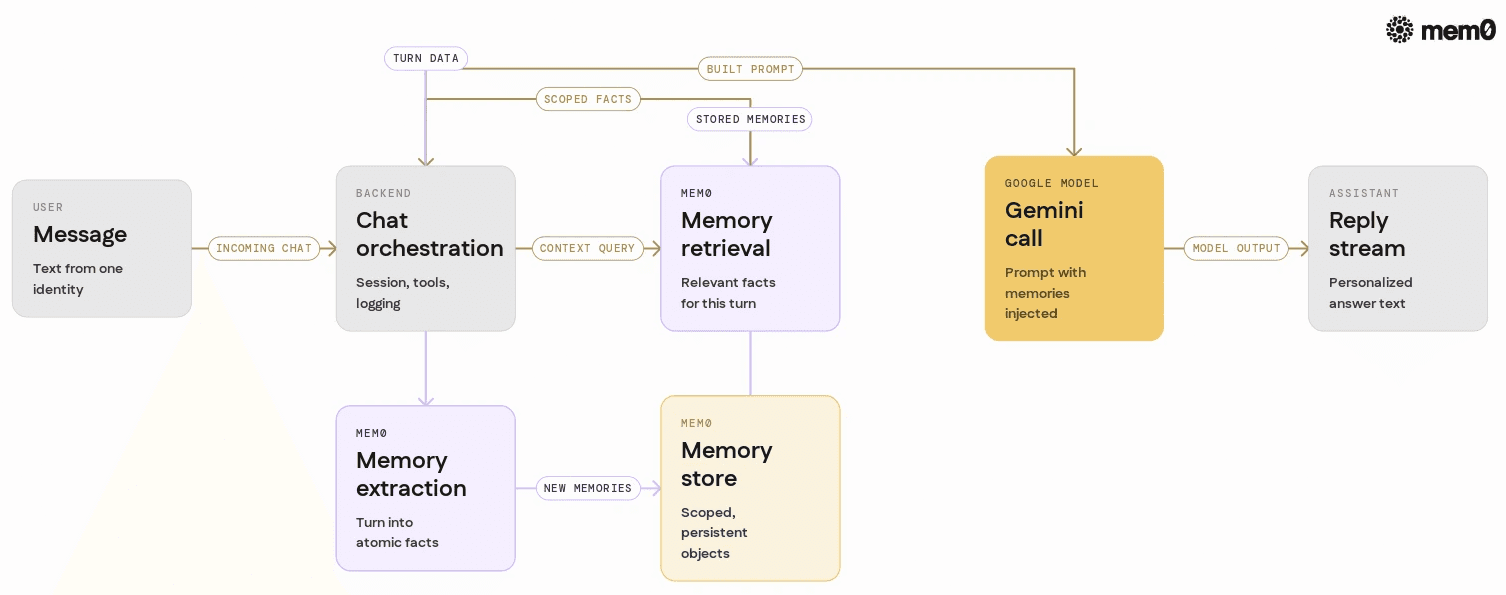
In a typical Google AI chatbot architecture, the request pipeline might look like this:
User sends a message.
Backend collects current session history.
Optional tools run, for example, search or database queries.
Backend builds a prompt and calls the model.
Model responds and the response is streamed to the user.
Logs and analytics are stored.
With Mem0 integrated, the pipeline becomes:
User sends a message.
Backend sends the new message (and optionally model reply) to Mem0 for memory extraction.
Backend queries Mem0 for relevant memories for this user or conversation.
Backend composes the prompt with: system instructions, retrieved memories, conversation snippets, and tool results.
Prompt goes to the Google AI model.
Response is streamed back.
Mem0 persists any new memories derived from this turn.
This pattern gives the agent stable, structured memory that persists across channels, devices, or models.
Example: Integrating Mem0 with a Google AI chat flow in Python
The following Python example shows a minimal integration. It assumes:
Google AI models are accessed through
google-generativeai.Mem0 is used via its Python SDK.
A simple user ID is available for each request.
💡 You'll need a free Mem0 API key to follow along. Get one at app.mem0.ai, free tier, no credit card required.
This example keeps the logic simple, but several important patterns are already present:
User identity is used to partition memories.
Mem0 is queried before the model call to inject user-specific context.
Mem0 is updated after each turn so future interactions benefit.
In a production system, engineers can add scopes for agents, projects, or teams, and attach metadata to memories to control retention and retrieval.
Where Google-style memory patterns stop being enough
Even with good use of context windows and databases, AI agents built on Google AI models encounter predictable memory pain points:
Cross-channel continuity: A user interacts via web, mobile, and email. Without a central memory, each channel has partial context. The agent behaves inconsistently.
Multi-agent coordination: Several agents collaborate on tasks such as support triage, sales, or operations. If each agent has its own siloed memory, they duplicate questions and miss dependencies.
Personalization drift: Preferences inferred from logs or heuristics can conflict or become stale. Without explicit memory objects and governance, the system cannot easily correct or prune knowledge.
Migration between models or vendors: When an organization wants to move from one model to another, training data and prompt strategies can be migrated. Raw "memory" embedded in a provider-specific format cannot.
Compliance and deletion: Regulations may require per-user data inspection and deletion. Unstructured logs and ad hoc vector databases make it difficult to know what the system "remembers" about any user.
These issues are not specific to Google AI. They are shared across LLM stacks, and they show that the core memory problem is architectural, not a feature that any single model API can solve fully.
How Mem0 addresses the core memory problem
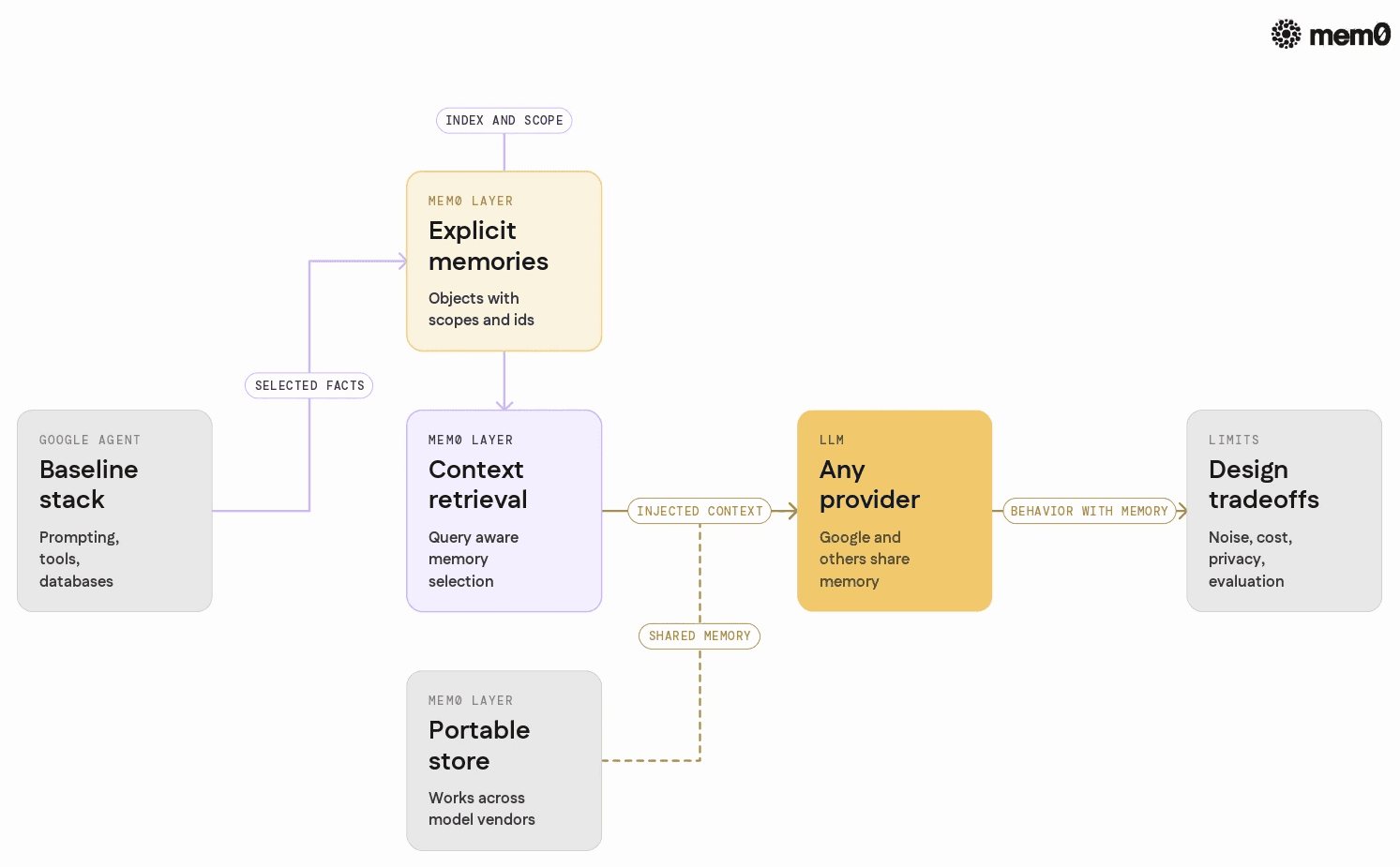
Mem0 focuses on the memory layer as a first-class component. In the context of Google AI chatbots and agents, it provides:
Explicit memory objects: Instead of raw logs, Mem0 stores discrete memories. Each memory has content, timestamps, identities, scopes, and metadata. This makes memory inspectable and manageable.
Context-aware retrieval: Mem0 retrieves memories conditioned on the current query, user, and agent. This reduces prompt bloat and focuses the model on what matters.
Multi-tenant and multi-agent support: Memories can be scoped and segmented. An organization can define different memory graphs for different products, agents, or environments.
Portability across models: The memory layer does not depend on a specific LLM provider. An agent can call Google AI today and another provider tomorrow, while keeping the same Mem0 instance as its memory.
Open-source and self-hostable options: For scenarios where data residency or internal policies matter, Mem0 can run in the organization’s infrastructure, while Google AI models run in the cloud.
The net effect is that memory becomes a stable, versioned asset, not an incidental side effect of prompts.
Limitations of current memory patterns in LLM agents
Even with Mem0 or similar memory layers, memory in LLM agents has real limits that engineers should respect:
Noise accumulation: If the system stores every utterance as memory, retrieval quality degrades and irrelevant details crowd prompts. Thoughtful memory extraction and pruning policies are essential.
Ambiguous or conflicting facts: Users change jobs, preferences, and projects. The memory system must support versioning and conflict resolution. No automatic approach is perfect, and human-in-the-loop review may be needed for high-stakes domains.
Latency and cost trade-offs: Each memory query and larger prompt adds latency and token cost. Aggressive retrieval or large memory payloads can slow agents and increase spend.
Evaluation complexity: Testing an agent that uses persistent memory is harder than testing a stateless chat endpoint. Reproducible evaluation requires control over memory state and seeds.
Security and privacy boundaries: Memory can propagate sensitive data between contexts. Engineers must design strict scoping rules and enforce access controls, especially in multi-tenant systems.
Model behavior under injected memory: LLMs sometimes overfit to injected memories, hallucinate details, or misinterpret stale information. Guardrails and careful prompt design remain necessary.
These limitations do not negate the value of memory. They highlight that memory is a design problem, not a simple switch to flip.
Frequently Asked Questions
Q. How does memory in Google AI chatbots differ from application memory?
Memory inside Google AI models is limited to what is in the current prompt and context window. Application memory lives outside the model as stored data that persists across requests, sessions, and even across model providers.
Q. Why is a dedicated memory layer needed if the context window keeps growing?
Larger context windows help within a single interaction but do not solve persistence, governance, or portability. A dedicated memory layer tracks explicit facts over time, supports deletion and auditing, and works regardless of context size or provider.
Q. How does Mem0 decide what to store as memory from a conversation?
Mem0 uses LLM-powered extraction and configurable rules to convert raw chat turns into structured memories. Engineers can define which types of facts matter, such as preferences or account details, and Mem0 will focus on those instead of storing everything.
Q. Can Mem0 store non-chat data for Google AI agents, such as CRM or ticketing info?
Yes, Mem0 can ingest structured or semi-structured data from external systems. This allows agents to use unified memory that includes user chats, CRM fields, support tickets, and other sources, all retrievable through a consistent interface.
Q. How is user privacy handled when using Mem0 with Google AI models?
Mem0 supports scoping and segmentation so that memories are isolated per user, tenant, or project. For stricter requirements, teams can self-host Mem0 inside their infrastructure and carefully control which memories are injected into prompts sent to external model APIs.
Further Reading
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or
self-host mem0 from our open source github repository.
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

