



Long-term memory is the difference between a one-off chatbot and a persistent agent that users can rely on daily. For production AI systems, memory is not a nice-to-have. It is a core part of user experience, personalization, and task continuity.
Yet most long-term memory implementations are brittle. They mix business logic with storage code, depend on ad hoc vector stores, and are hard to evolve as agents grow more complex.
This article explains how to think about long-term memory for AI agents, the architectural building blocks, where simple patterns break, and how Mem0 fits as a dedicated memory layer. The focus is on engineers who need predictable, debuggable behavior in production.
What long-term memory means for AI agents
For agents, long-term memory is the ability to persist and retrieve relevant information across sessions, tasks, and time frames that exceed a single model context window. It complements short-term conversation history and tool outputs.
Common categories of long-term memory include:
User profile memory: preferences, identity, constraints, roles.
Task memory: ongoing project state, partial results, commitments.
Knowledge memory: documents, past decisions, explanations.
Interaction memory: patterns from previous conversations and actions.
Key properties that production systems care about:
Persistence across sessions: Memory survives reconnects, restarts, and model upgrades.
Selective recall: Only relevant slices of memory are injected into prompts, not entire histories.
Editable history: Operators can inspect and correct memory, and the system can forget.
Scoped isolation: Memory is scoped correctly by user, tenant, and sometimes agent.
Long-term memory is not just a bigger context window. It is a separate system that decides what to store, how to retrieve, and how to feed that back into model reasoning.
Core components of long-term memory
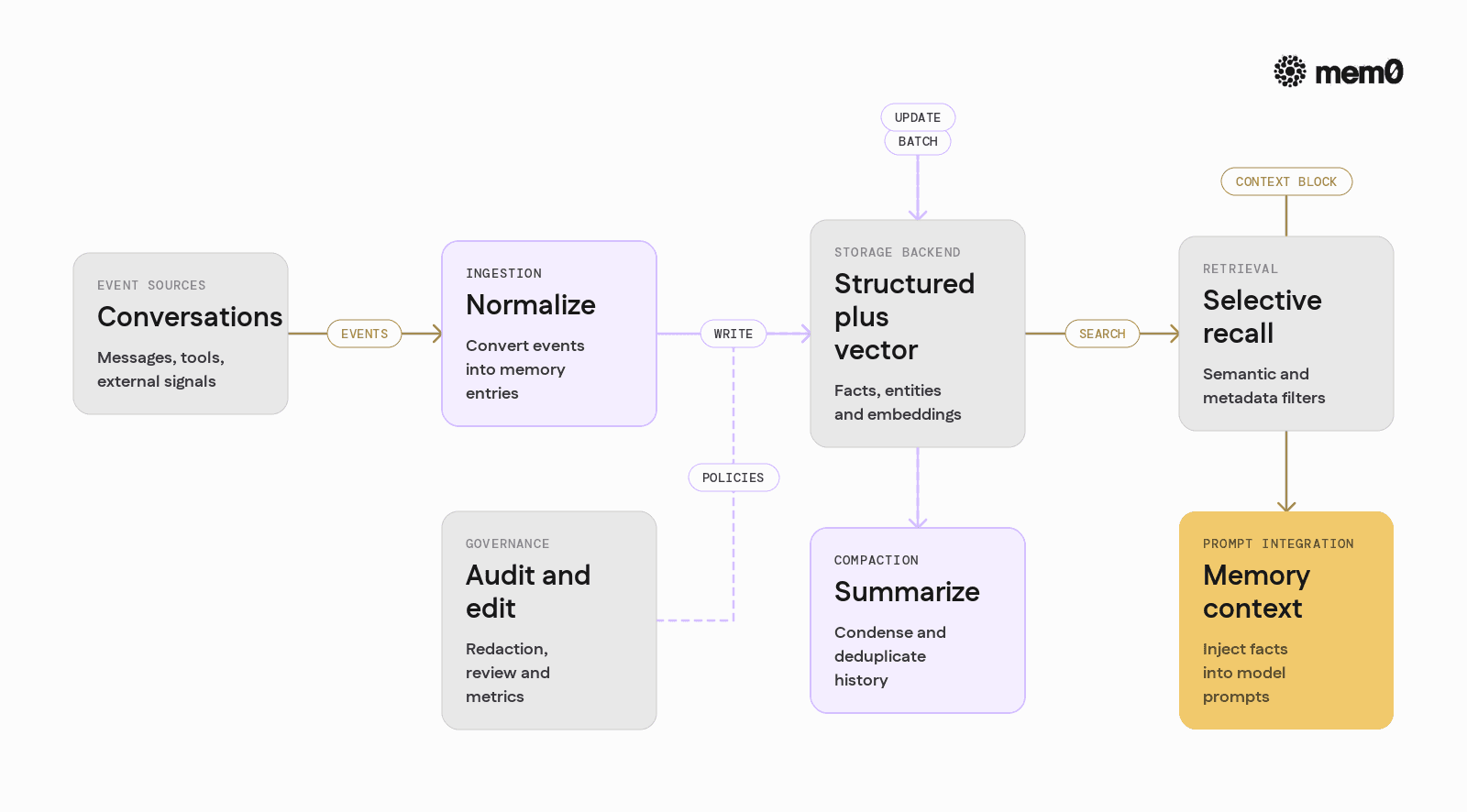
A production memory system for agents typically includes these components:
Ingestion pipeline: Ingests events and facts from conversations, tools, and external systems. It converts them into normalized memory entries.
Storage backend: Persists memory using one or more stores:
Structured store for entities and facts.
Vector or semantic store for unstructured context.
Retrieval engine: Given a query or context, retrieves relevant memories using:
Semantic similarity.
Metadata filters (user, type, timestamp).
Recency/importance scoring.
Summarization and compaction: Compresses longer histories into summaries. Reduces duplication and manages storage growth.
Prompt integration: Injects retrieved memory into prompts in structured ways:
System messages for long-lived facts.
Context sections for recent or situational memories.
Governance and observability: These provide hooks for:
Redaction and deletion.
Auditing and debugging.
Metrics and monitoring.
Without a clear separation of these concerns, agents tend to accumulate ad hoc logic: inline SQL calls in tools, hardcoded embeddings, random Redis keys, and manually truncated histories.
Common patterns for agent memory
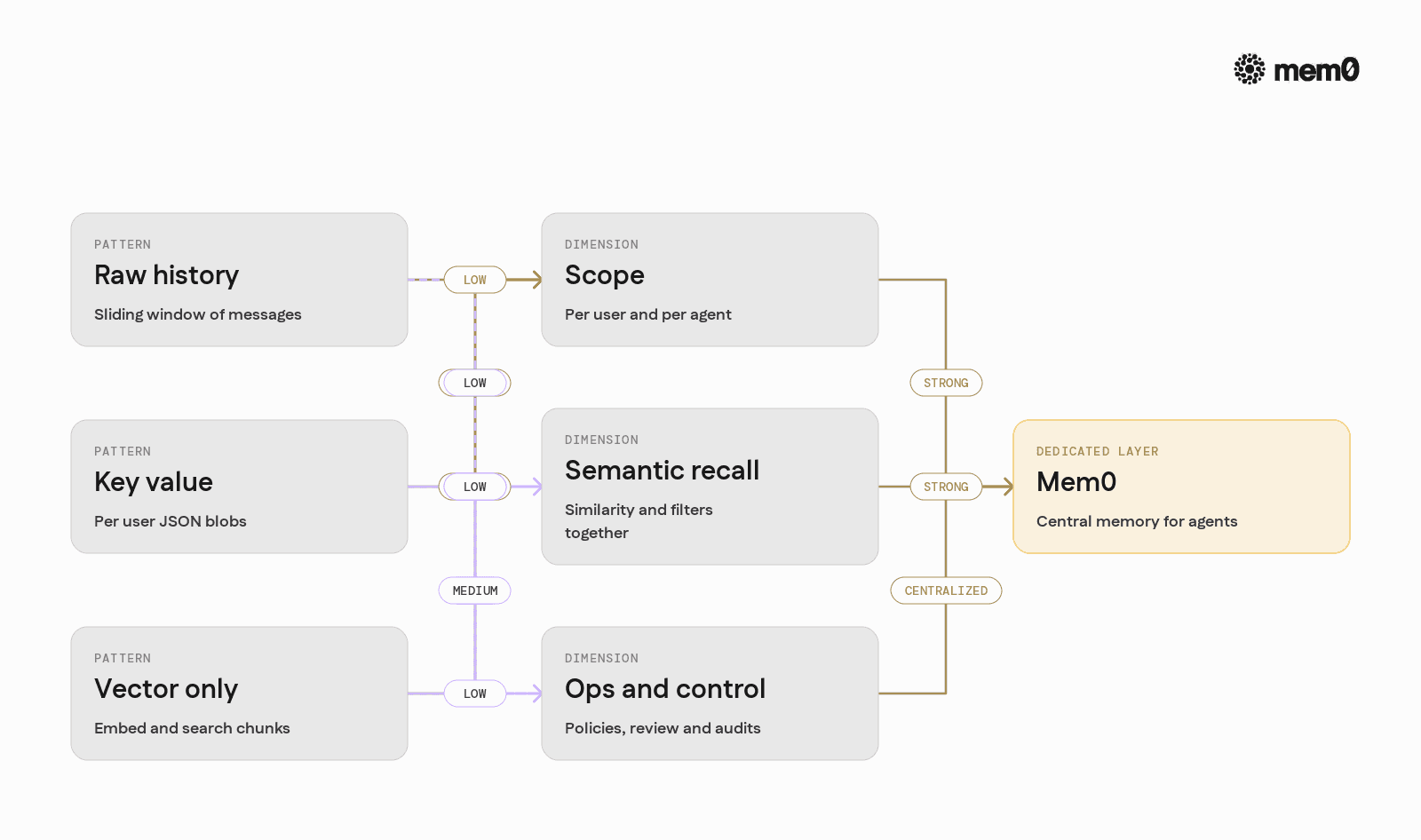
Most AI engineers start with one of a few patterns. They vary in complexity and reliability.
Pattern 1: Raw chat history
The simplest pattern is to keep a sliding window of messages and pass that to the model each turn.
Strengths:
Easy to implement.
Works for short-lived interactions.
Weaknesses:
Context window limits.
No cross-session persistence.
No ability to prioritize important facts.
This is short-term memory only, not long-term.
Pattern 2: Key-value store per user
Next, many systems add a key-value store like:
user:123:profile→ JSON with preferences.user:123:last_project→ summary text.
The agent or tools read and write these keys. This gives:
Simple persistence.
Structured access.
Weaknesses:
No semantic retrieval.
Hard to evolve schema.
Logic for when and how to update lives everywhere.
Pattern 3: Vector store with embeddings
A more advanced pattern stores chunks of text (conversation excerpts, documents, summaries) in a vector database. Each inference call retrieves the top-k most similar items to the current query.
Strengths:
Semantic matching across large memory.
Works with arbitrary unstructured data.
Weaknesses:
Requires good chunking and metadata.
Often lacks higher-level concepts like importance, type, or lifespan.
Tied closely to a specific embedding model / DB.
Pattern 4: Hybrid memory layer
Production agents often need:
Structured and unstructured memory.
Semantic and metadata filters.
Different lifetimes for different memory types.
Centralized control and observability.
This is where a dedicated memory layer like Mem0 fits. It wraps these patterns into a coherent system so application code does not need to reimplement ingestion, retrieval, and consolidation logic.
Challenges in long-term memory for agents
In practice, long-term memory introduces specific engineering challenges. These include:
Overfitting and hallucinated memory
If the model treats every retrieved context as ground truth, it can:
Repeat outdated preferences.
Ignore user corrections.
Invent facts based on misaligned retrievals.
Agents need mechanisms to:
Update or invalidate older memories.
Prefer recent corrections.
Distinguish between stable facts and ephemeral context.
Context flooding
Naive retrieval that injects too many memories leads to:
Prompts exceeding token limits.
Distracting or irrelevant context.
Slow response times.
Production systems need scoring strategies that balance relevance, recency, importance, and diversity, and they may summarize earlier memory into compact representations.
Multi-agent and multi-tenant scenarios
In more complex stacks:
Multiple agents share the same user.
Agents have specialized roles.
Tenants require strict isolation.
The memory system must support:
Namespaces or scopes.
Per-agent memory policies.
Clear boundaries for security and compliance.
Tools and external state
Agents with tools interact with:
CRMs.
Databases.
External APIs.
Not all external state should be mirrored in long-term memory. A memory layer needs policies for what to store as memory versus what to query on demand.
How Mem0 models agent memory
Mem0 is a memory layer designed specifically for LLM and agent workflows. It focuses on being:
Model-agnostic: usable with any LLM stack.
Agent-friendly: fits multi-agent and tool-based designs.
Persistent and inspectable: via API and storage backends.
At a conceptual level, Mem0 treats memory as:
Entries: atomic pieces of information created from events like messages, tool outputs, or external data.
Metadata: attributes like user id, agent id, type, and importance.
Indexes: semantic and structured indexes that support retrieval.
Mem0 handles several core tasks:
Memory creation: Mem0 accepts text or structured payloads and turns them into memories with optional embeddings and metadata.
Scoped retrieval: It retrieves relevant memories by query text or context, filtered by user, agent, or other metadata.
Summarization support: It also provides hooks for summarizing large histories or consolidating repeated information.
Persistence and self-hosting: Mem0 lets teams use a managed API or run their own stack, which is important for production deployments.
Instead of wiring memory logic directly inside agents, developers integrate Mem0 as a separate component, similar to how they integrate a database or cache.
Integrating Mem0 into an AI agent
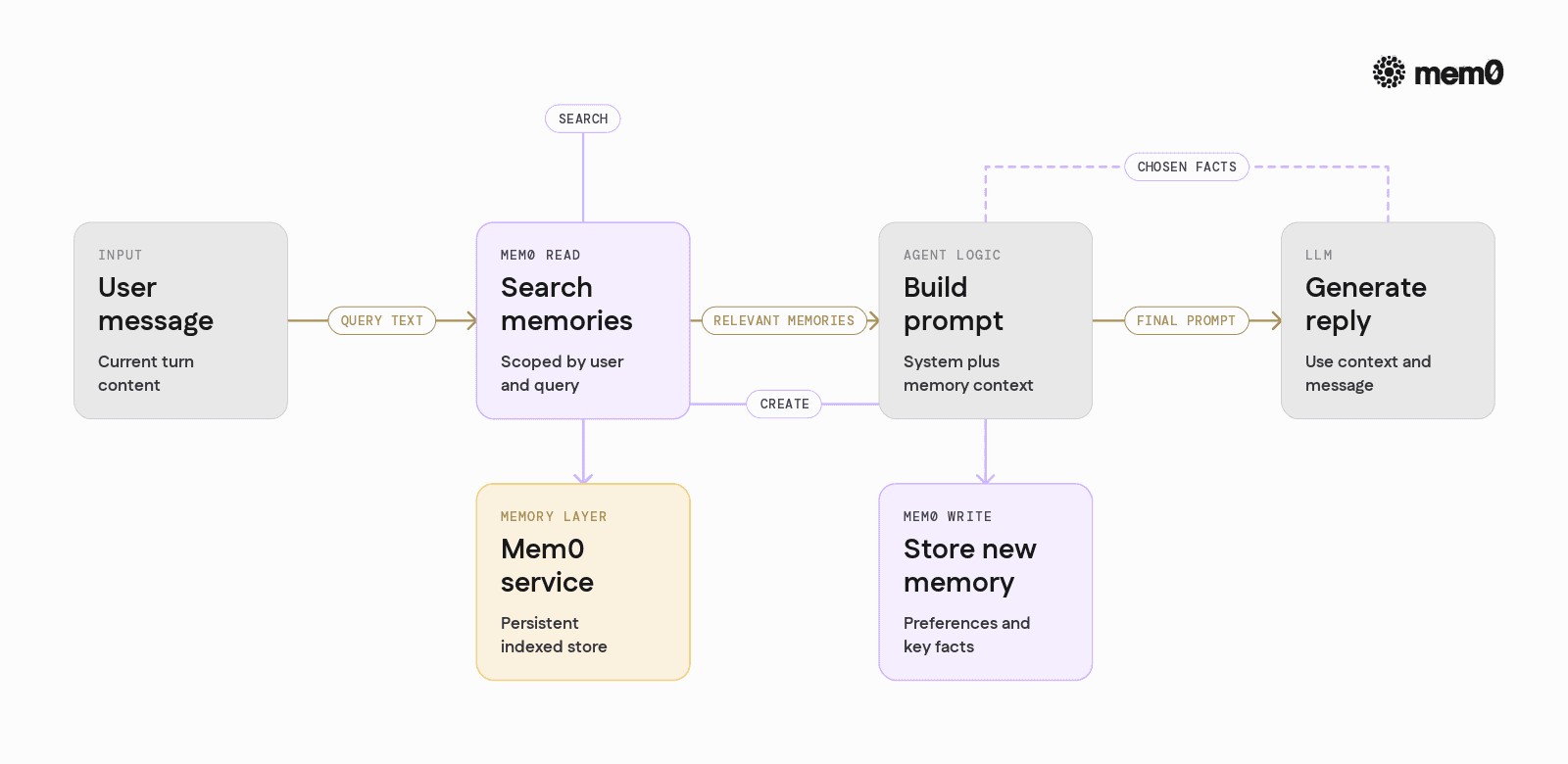
This section walks through a simple Python integration that uses Mem0 as the memory layer for a chat-style agent. The same patterns extend to tool and multi-agent setups.
Assumptions:
Python environment.
An LLM client (example uses OpenAI but can be replaced).
Mem0 Python client installed.
Basic Mem0 setup
Below is a minimal setup for Mem0. But first, go to app.mem0.ai, sign up for free, and copy your API key from the dashboard.
Mem0 is instantiated once and reused. The same client can be shared by different agents or services.
Storing user-specific memory
Suppose the agent learns user preferences during a conversation. The following function writes memory scoped to a user:
Usage example when the user says a preference:
Mem0 handles embedding, indexing, and persistence. Application code only describes what the memory represents.
Retrieving memory for contextual prompts
When generating a response, the agent can query Mem0 for relevant memories for the current user:
Integrate into a chat loop:
This pattern does the following:
Uses Mem0 to retrieve relevant context for the current user.
Injects the context into the prompt as a separate block.
Stores new messages as memory for future reference.
In production, memory creation would be selective. For example, only store explicit preferences, commitments, and key facts, not every message.
Structured and semantic memory with Mem0
Long-term memory benefits from combining explicit structure with semantic indexing. Mem0 supports both through metadata and semantic search.
Structured metadata
Metadata helps restrict retrieval:
user_id: scope by user.agent_id: scope by agent or role.type: classify memory (preference, task, profile, summary).ttlorexpires_at: enable time-based policies.
Example of storing task memory:
Retrieving only task-related memory:
Semantic recall
Mem0’s search uses embeddings under the hood. This allows the agent to retrieve context even if the wording differs.
For example, if the user previously said:
"Please do not schedule meetings after 5pm my time."
A later query:
"What was the scheduling constraint again?"
Can still match that memory via semantic similarity, even though no keywords are shared.
Comparison of memory approaches
The table below compares three approaches to long-term memory for agents.
Approach | Pros | Cons | Suitable for |
|---|---|---|---|
Raw chat history | Simple, no extra infra | No persistence, context-limited, noisy | Prototypes |
DIY vector + key-value | Flexible, tailored to app | Duplicated logic, complex maintenance | Small teams with narrow scope |
Dedicated memory layer | Centralized rules, semantic and scoped | Requires integrating a new component | Production agents and multi-agent systems |
Mem0 belongs in the last category. It focuses entirely on the memory problem so agent code can stay closer to business logic and tool orchestration.
Applying Mem0 in production agents
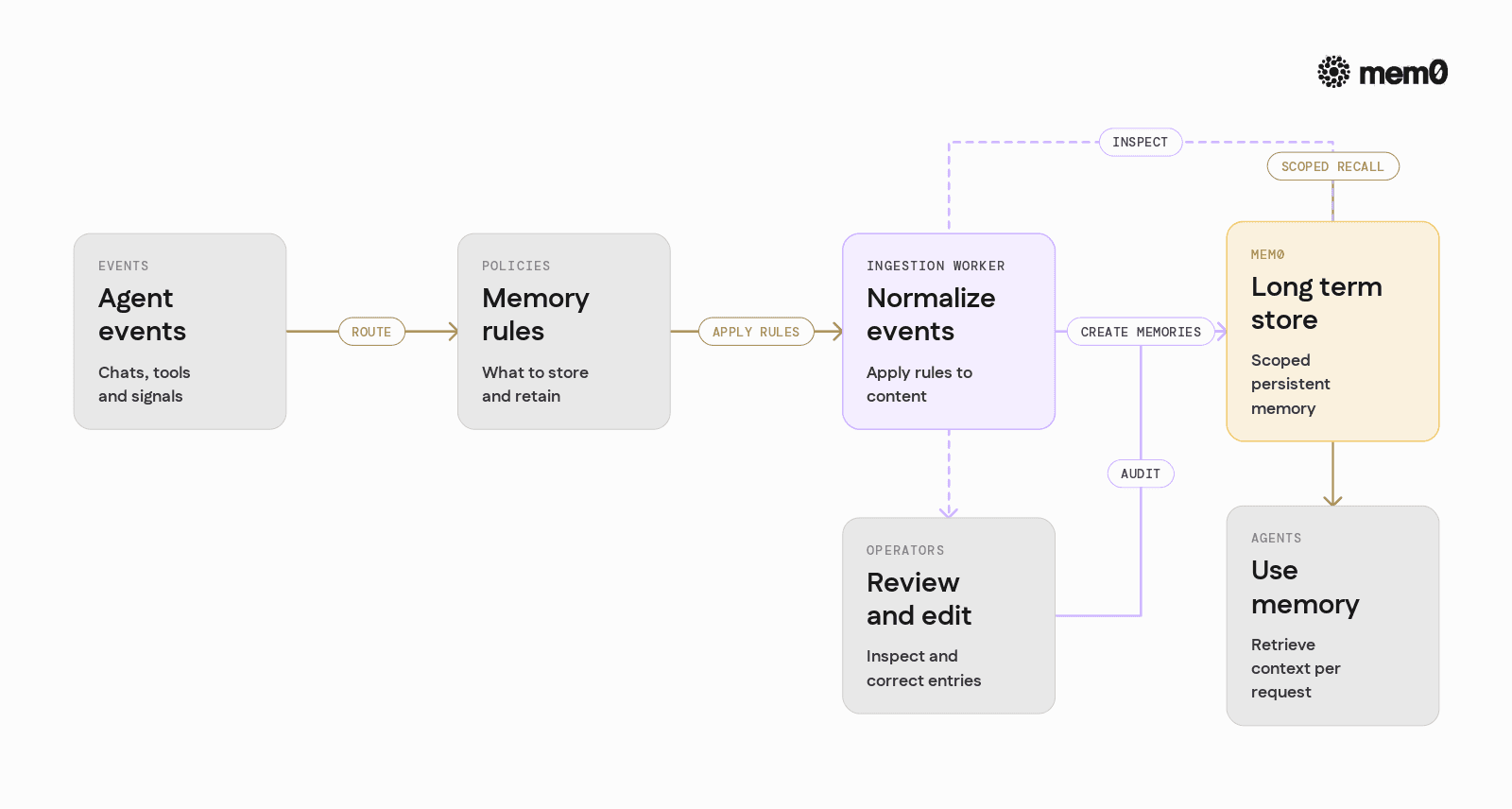
To make Mem0 effective in production, teams typically follow a few patterns.
Memory policies
Define explicit policies describing:
What to store:
Preferences, recurring tasks, long-lived facts.
Summaries of long conversations.
What not to store:
One-off questions.
Sensitive data without explicit consent.
How long to retain each type of memory.
These policies can be encoded via metadata and processing pipelines around Mem0.
Event-driven ingestion
Instead of writing directly from every agent call, consider an event pipeline:
Conversation messages.
Tool results.
External signals.
An ingestion worker:
Reads events.
Applies rules to decide what to store.
Calls Mem0 with normalized content and metadata.
This decouples memory from synchronous response paths and allows more control over what becomes part of long-term memory.
Observability and review
For high-stakes agents, operators need to:
Inspect memories for a given user.
View which memories were retrieved in each response.
Delete or correct problematic entries.
Mem0’s API and storage abstraction make it easier to implement dashboards and admin tools that give this visibility.
Limitations of the long-term memory pattern
Long-term memory does not solve every problem in agent design. It has limitations that teams should consider.
Drift over time: If memory accumulates without consolidation, older or redundant entries can influence outputs in unexpected ways. Periodic summarization, deduplication, and pruning are required.
Incorrect or biased memories: When agents misinterpret user statements, those mistakes can become part of memory. Human review, constraints, and explicit correction mechanisms are important.
Context overload: Even with semantic retrieval, feeding too much memory into prompts can confuse models. Good scoring and summarization strategies are essential to avoid overloading the model with marginally relevant context.
Schema evolution: As agents evolve, memory structures and metadata requirements change. Systems must support migration, re-embedding, and reindexing strategies.
Compliance and privacy constraints: Long-term storage raises questions about data residency, consent, and retention. Teams must align memory policies with compliance requirements, and sometimes must disable or narrow memory for specific environments.
Mem0 addresses many infrastructural concerns but cannot replace clear product and governance decisions around what memory should exist and how it should be used.
Frequently Asked Questions
Q. What is the main difference between long-term memory and regular context history for agents?
Regular context history is just the recent conversation or tool outputs that fit in a single prompt. Long-term memory is persisted across sessions and retrieved selectively based on relevance and metadata. It survives restarts and model changes, and it requires dedicated storage and retrieval logic.
Q. How does Mem0 integrate with existing LLM frameworks and toolchains?
Mem0 operates as a separate memory service that can be called from any Python or HTTP-based stack. Agents can create and search memory using Mem0’s API, then pass retrieved context into prompts before calling their LLM of choice. It integrates alongside existing orchestration frameworks rather than replacing them.
Q. When should an engineer introduce a dedicated memory layer like Mem0?
A dedicated memory layer becomes useful once agents need consistent behavior across sessions, personalization for many users, or complex multi-agent workflows. If ad hoc key-value stores and vector calls are spreading across the codebase, it is usually time to centralize memory management. Starting earlier can simplify later refactors.
Q. How does Mem0 handle different types of memory such as preferences, tasks, and documents?
Mem0 uses content plus metadata to classify and scope memories. Developers can tag entries as preferences, task state, document snippets, summaries, or other custom types, and then filter retrieval by these tags. Semantic indexing allows similar retrieval behavior across different types while still respecting metadata filters.
Q. Why not just store everything and always retrieve the top memories for each query?
Storing everything creates noise, increases storage costs, and can degrade model performance by injecting irrelevant context. Retrieval also becomes less precise as the index fills with low-value entries. Selective storage, summarization, and well-scoped retrieval ensure that only useful and accurate context influences the agent.
Q. How do long-term memory systems interact with compliance and privacy requirements?
Long-term memory systems must support deletion, scoping, and retention policies aligned with regulations and internal standards. Engineers should design memory schemas that isolate tenants, use metadata for retention rules, and expose administrative controls for inspection and erasure. Mem0 can be deployed in environments that match the organization’s compliance needs, including self-hosting.
Further Reading
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai, or
Self-host mem0 from our open-source GitHub repository.
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

