



Most customer service chatbots forget everything the moment a session ends. The customer explains their billing problem on Monday, comes back on Wednesday, and has to explain it all over again. That repetition is the single fastest way to erode trust in a support bot.
This is a tutorial for building a customer service chatbot that remembers. You will wire up a working Python chatbot that reads a customer's history before it answers and writes new facts back after, using Mem0 as the memory layer and the OpenAI API for generation. The full working example is two scrolls down. The architecture, schema design, and tradeoffs come after, once you have seen the code run.
Why do customer service chatbots need real memory?
Customer service chatbots have moved from FAQ bots to workflow agents that handle billing questions, support tickets, and account changes. As the scope expands, so does the expectation that these bots remember customer context across sessions.
Without persistent memory, a customer has to repeat basic information in every conversation, which increases friction and reduces trust. For engineers, the challenge is maintaining accurate, queryable memory across thousands or millions of customers, without leaking data or breaking latency budgets.
Persistent memory delivers three things in customer service: personalization based on history and preferences, context continuity across sessions and channels, and operational efficiency through reuse of past resolutions. The difficulty is not storing data, it is storing the right data in a way that language models can reliably use. That is the problem Mem0 targets.
What does persistent memory mean in customer service
In customer service, persistent memory has a specific shape. It is not just long prompts or conversation logs. It is structured knowledge associated with identities.
Typical memory objects for customer service bots include:
Customer profile: identifiers, preferences, products or plans, risk flags.
Interaction history: previous issues, resolutions, escalations, satisfaction scores.
Operational state: open tickets, pending shipments, and billing cycles.
Soft signals: tone patterns, typical concerns, preferred communication style.
An effective memory layer must support identity-aware storage and retrieval, flexible schemas (since useful facts are not known in advance), time-aware behavior such as prioritizing recent events, and fine-grained control over what is stored, updated, or forgotten. Mem0 provides these mechanics as a dedicated layer, which avoids pushing all of this logic into the agent code or the LLM prompt.
Build it: a memory-aware customer chatbot in Python
Here is a minimal but working integration. It reads customer memory from Mem0, builds a prompt with that context, calls the LLM, and writes the new interaction back. Install the two dependencies first:
👉Wanna give it a try? Get a Mem0 API Key and try it yourself.
Run this twice with the same customer_id. On the second run, the billing complaint from the first conversation is already retrievable, so the bot can acknowledge the prior issue instead of asking the customer to start over. That is the entire value of persistent memory in one loop: read before answering, write after resolving.
This leads to example stores every interaction for simplicity. In production, you will want a more selective write policy, covered below, so memory stays clean. You can run this now with a free key from app.mem0.ai.
Refining the write step for production
Storing raw turns is fine for a demo, but at scale, it produces noisy memory and inflates retrieval cost. The common production pattern is to summarize each interaction into a compact fact before saving, often with a separate LLM call, and to write once the conversation resolves rather than on every turn.
For example, after a billing chat, the agent could save a single summary:
"Customer disputed line item for streaming package on May bill, accepted partial credit and agreed to keep package."
This is compact and easy for the LLM to use at the start of the next session. In production, you would also add role-specific metadata such as ticket IDs, plan codes, or SLA indicators, and guards to avoid storing sensitive fields based on your data policies. The core read-write shape stays identical; only what you write changes.
Core architecture for a memory-aware customer chatbot
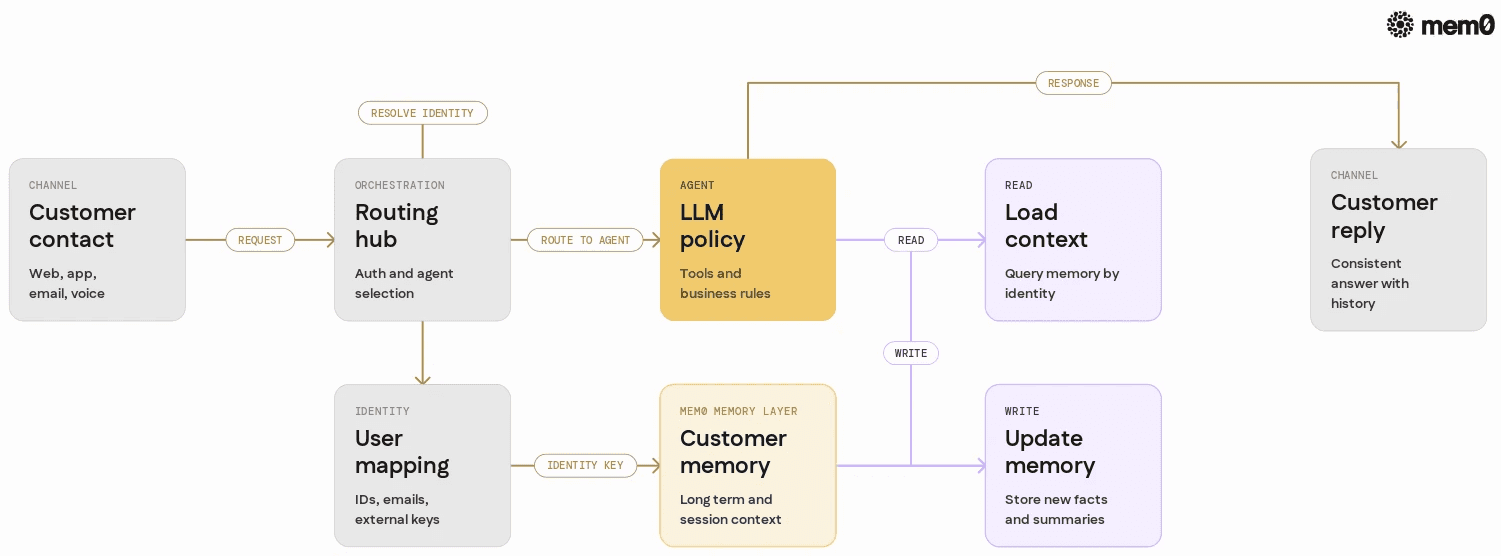
For production systems, memory-aware chatbots typically follow a layered design:
Channel layer: web chat, mobile app, email, voice transcription, and internal tool integrations.
Orchestration layer: routing, authentication, rate limiting, and agent selection.
Agent layer: LLM-based policies, tools for backend APIs, and business rules.
Memory layer: long-term customer memory, short-term conversation context, analytics storage.
Mem0 sits in the memory layer and integrates with the agent layer through a simple API. The agent reads memory at the start of an interaction, writes new memory during or after handling the request, and optionally updates or deletes memory as state changes.
A typical request cycle looks like this:
Identify the customer using authentication or a session token.
Query Mem0 for the customer's long-term memory.
Build a prompt that includes relevant memory snippets.
Let the LLM select actions, call tools, and generate the response.
Extract new facts from the conversation.
Save these facts back into Mem0 for future sessions.
This pattern isolates memory concerns from agent logic, while keeping memory grounded in the customer identity.
How Mem0 stores customer memory
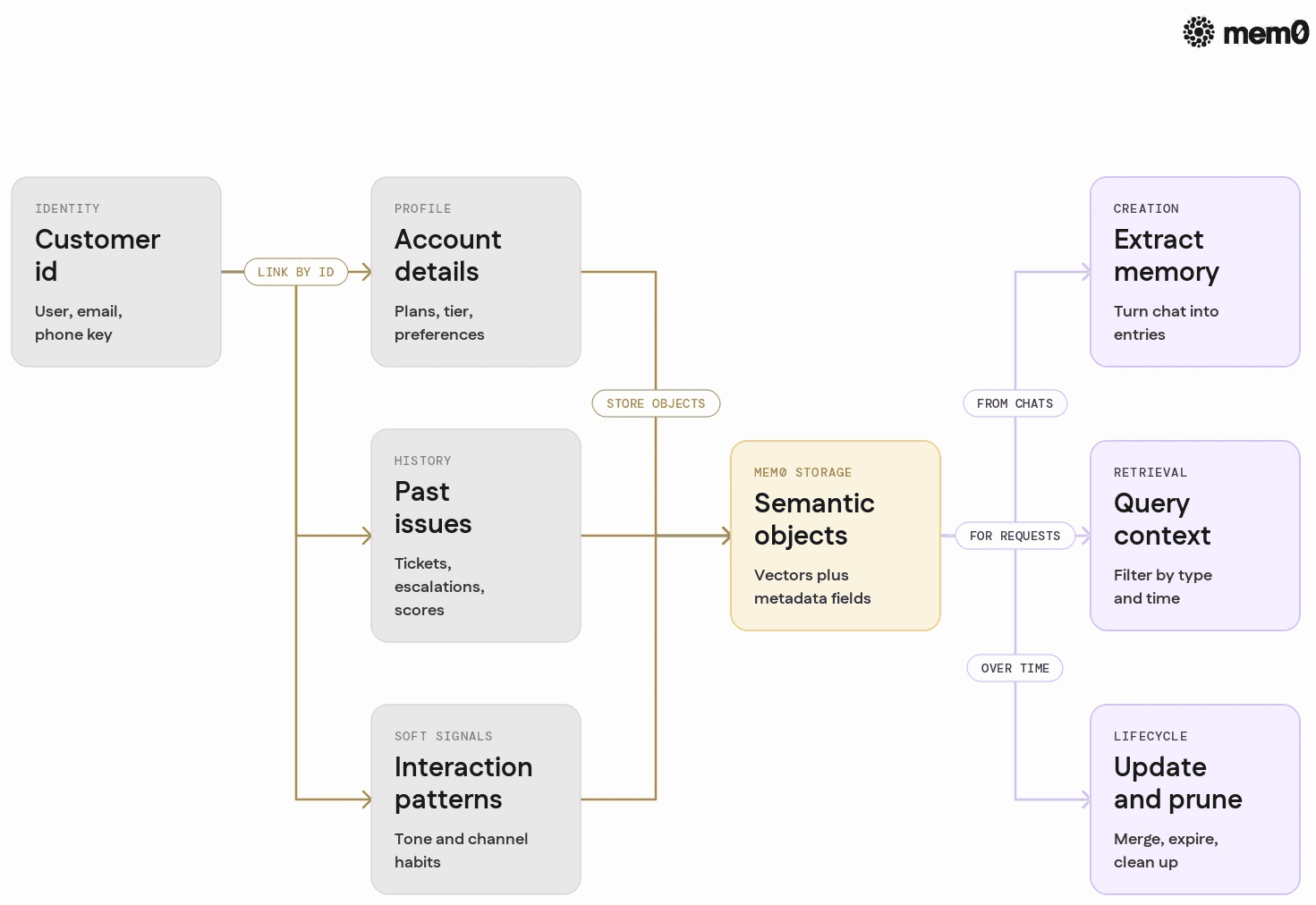
Mem0 treats memory as semantic objects keyed by identities. It combines three ideas:
Identity-centric memory: Each memory item is tied to entities such as user IDs, emails, or phone numbers, so agents fetch the right context for a specific customer in one call.
Semantic representation: Mem0 stores memory in vector form and maintains structured metadata, which allows flexible querying such as "recent billing issues" or "prior interactions mentioning upgrades".
Automatic extraction: Instead of requiring engineers to define all fields, Mem0 can extract salient memory from raw text conversations and store it as atomic entries.
At a high level, Mem0 abstracts memory creation (what parts of a conversation become long-term memory), retrieval (which pieces are relevant now), and lifecycle (when entries should be updated, merged, or pruned). The agent code interacts with Mem0 through Python or REST without managing embeddings, indexes, or schemas directly.
Designing memory schemas for customer service
Even though Mem0 can operate on raw text, best results come from a simple logical schema that guides what is stored. It does not need to be rigid tables, but it helps avoid noisy memory.
Common memory categories in customer service chatbots:
Identity and profile: basic details, product subscriptions, tier level, region, and preferences.
Support history: summary entries like "Reported slow connection on 2024-06-01, resolved after router reset" with tags such as
issue_type="connectivity".Risk and special handling: items like "High churn risk", "VIP customer", or "Prefers email over phone".
Operational state: active tickets, RMA status, unpaid invoices, and scheduled technician visits.
With Mem0, each stored text can carry metadata tags expressing these categories. Retrieval can then filter not only by semantic similarity but also by metadata such as type or date range.
Comparison of memory approaches in customer chatbots
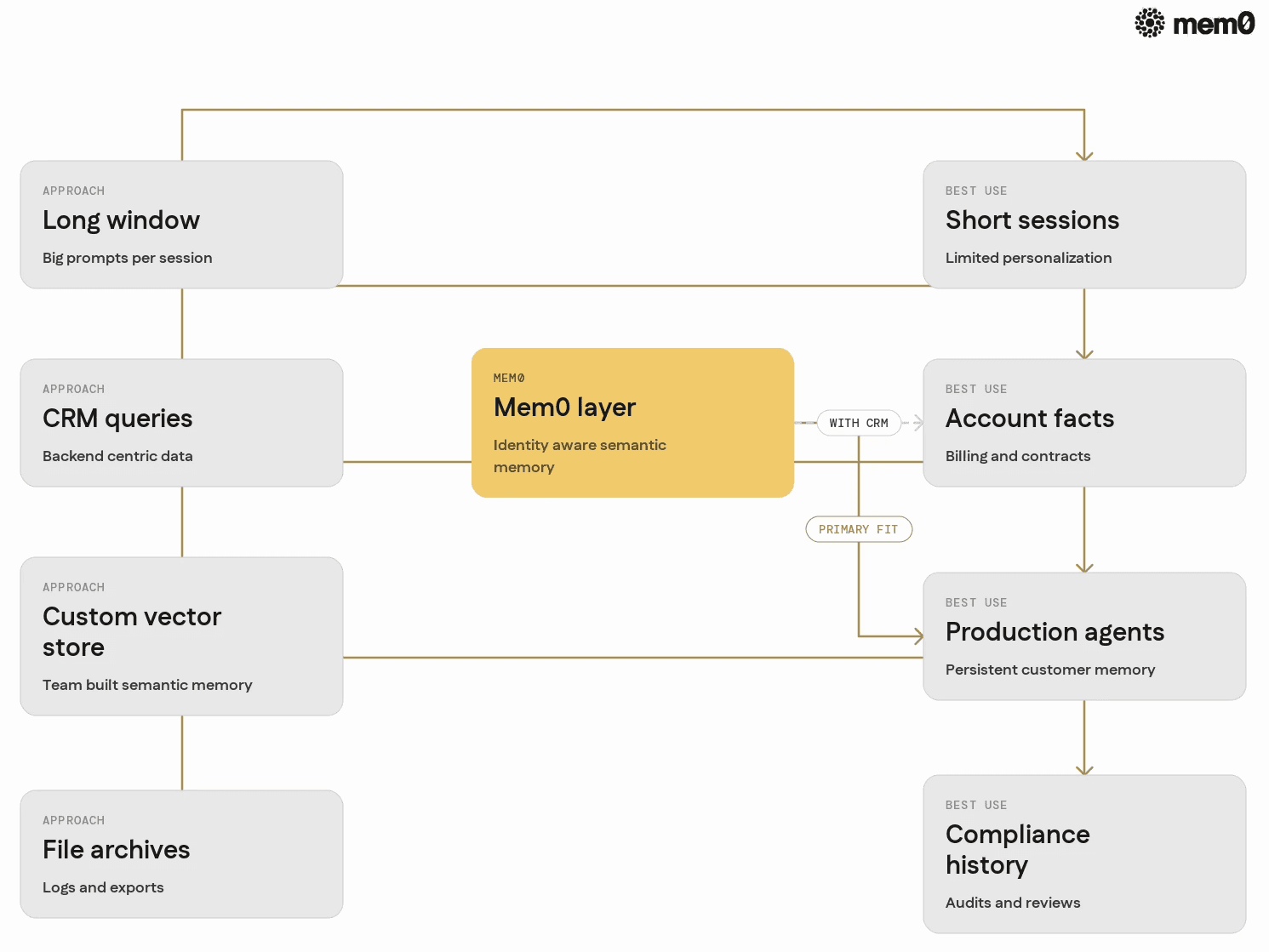
Engineers often try several memory patterns before choosing a dedicated layer. The table below summarizes common approaches.
Approach | Strengths | Weaknesses | Good for |
|---|---|---|---|
Long conversation window | Simple, no extra infra | Expensive tokens, loses older history, no identity linking | Short sessions with limited context |
Manual CRM queries | Precise, consistent backend data | Rigid schema, hard to capture soft signals | Account data and billing facts |
Custom vector store | Flexible text storage, good semantic recall | Requires indexing, identity management, lifecycle code | Teams with infra bandwidth |
File or document archives | Easy to audit, simple search | Poor real-time retrieval, weak semantics | Compliance, bulk history exports |
Mem0 memory layer | Identity-aware semantic memory, simple API | Extra dependency and integration work | Production agents needing persistent memory |
Mem0 sits between raw CRM integration and custom vector stores. It offers identity-aware memory storage and retrieval tailored to agents, while CRM systems remain the source of truth for hard business data.
Limits of persistent memory patterns in customer service
Persistent memory improves experience, but it introduces its own constraints. These limits belong to the pattern, not to Mem0 specifically.
Incorrect memory extraction: If the agent saves wrong interpretations, future sessions carry those errors. Design extraction prompts and validation checks.
Stale or conflicting memory: Contract changes, plan upgrades, and policy updates make memory obsolete. The system needs pruning, versioning, or timestamps for resolution.
Privacy and compliance constraints: Some regions restrict retention of personal data. Memory storage must respect deletion requests and retention limits.
Overfitting to rare events: If a single unusual conversation dominates memory, the agent may focus on it excessively. Aggregation and weighting help.
Latency from heavy retrieval: Fetching large memory sets and stuffing them into prompts affects response time and token cost. Tune retrieval limits and add summarization.
A dedicated memory layer simplifies implementation, but system behavior still depends on these upstream choices.
How Mem0 fits into production customer service agents
Mem0 helps with the three hardest aspects of memory for customer chatbots:
Identity-based memory access: Memory tied to user IDs so any channel can reuse it. Web chat, phone callback, and email all load the same context.
Semantic recall with structured metadata: Vector similarity combined with tags like
issue_type,priority, orchannel, so agents pull only relevant aspects for the current request.Minimal integration surface: A focused API for adding, searching, and managing memories, so agent code stays about business logic, not memory plumbing.
In typical production setups, Mem0 works alongside authentication and identity providers, CRM and ticket systems for transactional data, and logging and analytics stacks. Mem0 does not replace these systems. It acts as the long-term conversational memory layer that bridges past interactions with future decisions.
Frequently asked questions
Q. What kind of customer data should a chatbot store in persistent memory?
A chatbot should store interaction summaries, preferences, recurring issues, and handling rules such as special escalation paths. Hard transactional data like invoices or contracts can stay in backend systems and be referenced when needed.
Q. How does Mem0 differ from simply extending the LLM context window?
Extending the context window keeps more text in a single prompt but does not solve identity management or cross-session continuity. Mem0 provides identity-aware storage and retrieval, so the agent can recall relevant history for the same customer weeks later without sending all past conversations in every request.
Q. How does Mem0 handle multiple channels for the same customer?
Mem0 uses identifiers such as user IDs, emails, or external IDs to group memory across channels. As long as the system maps each channel session to the same identity, Mem0 retrieves shared memory regardless of source, which keeps the experience consistent.
Q. What is the best way to prevent sensitive data from being stored in memory?
The agent should follow data policies that exclude sensitive fields, and engineers can add filters before calling add(). In stricter environments, a separate sanitization step or an allowlist of memory types helps enforce compliance.
Q. What are the best chatbots for customer service that support memory?
Most off-the-shelf customer service platforms (Intercom, Zendesk, Freshdesk) offer scripted or retrieval-based bots, but persistent cross-session memory usually requires a dedicated memory layer. Building on an LLM plus a memory layer like Mem0 gives you the most control over what is remembered, how it is retrieved, and how long it is retained.
Further Reading
Glm 5.2 Mem0 Persistent Memory For Long Horizon Coding Agents
DiffusionGemma for AI Agents: Adding Persistent Memory With Mem0
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or
Self-host mem0 from our open source GitHub repository.
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

