



We don't talk about this enough, but persistent AI memory turns a one-time vulnerability into a permanent exploit. In a stateless system, prompt injection ends when the session closes. In a memory-enabled system, the injection sits in the database, waiting to be retrieved later. When the agent pulls this poisoned context, it treats the attacker's instructions as its own trusted history, allowing adversaries to control agent behavior indefinitely without maintaining active access.
I'm not dismissing the use of memory in AI agents. It's absolutely necessary. That said, you still need to handle security well and avoid rogue memories from getting stored. Research by Dong et al. (2025) on the MINJA (Memory Injection Attack) showed that attackers can poison an agent's long-term memory through regular queries, no special privileges needed, hitting over 95% injection success rate and 70% attack success rate. Those numbers got my attention.
Considering how important AI memory security issue is, I figured we should talk about it. What follows is everything I've found on the specific threats targeting agent memory, the defenses that actually work, and what a secure memory architecture looks like in practice.
TLDR:
Memory poisoning attacks against LLM agents are proven and documented, with success rates above 80% across multiple independent studies
Three primary attack vectors exist: query-based memory injection, backdoor poisoning of knowledge bases, and experience grafting for persistent behavioral drift
Defenses require a layered approach: input sanitization, memory isolation per user/session, cryptographic integrity checks, Mem0's memory expiration, and continuous monitoring
GDPR's right to erasure and data minimization requirements apply directly to AI memory stores
Mem0 provides built-in memory isolation, SOC 2 compliance, customizable inclusion/exclusion rules, and self-hosted deployment options for teams that need full control
Attack type | Access required | Persistence | Detection difficulty | Primary defense |
|---|---|---|---|---|
Memory injection (MINJA) | User-level queries only | Cross-session | High (entries appear benign) | Input sanitization + trust scoring |
Backdoor poisoning (AgentPoison) | Knowledge base write access | Permanent until cleaned | Very high (indistinguishable embeddings) | Memory isolation + integrity checks |
Experience grafting (MemoryGraft) | Indirect, via ingested content | Durable behavioral drift | Very high (trigger-free) | Anomaly monitoring + memory audits |
Why Is AI Agent Memory a Security Target?
By design, every session with an LLM was an isolated event. A prompt injection in one conversation couldn't touch the next. But as more agents started implementing persistent memory, the attack surface expanded. The memory store became a shared state layer that influences every future interaction, and anything that enters it can shape the agent's reasoning indefinitely.
Palo Alto Networks' Unit 42 team built a proof-of-concept where indirect prompt injection planted malicious instructions into an agent's memory through a compromised webpage. Those instructions survived session restarts and got incorporated into the agent's orchestration prompts in later conversations, silently exfiltrating conversation history. The session ended. The attack didn't.
This sort of attack is difficult to catch because of how easily it can get abstracted within the thousands of memories that get created regularly. The A-MemGuard defense framework research (2025) found that even advanced LLM-based detectors miss 66% of poisoned memory entries. Something like "always prioritize urgent-looking emails" reads as perfectly reasonable on its own. In the context of a phishing attack, it directs the agent to favor the attacker's message. The malicious intent only shows up when that entry gets combined with a specific query context.
The Trust Boundary Problem
An agent trusts its own memory because that's how memory is supposed to work. When retrieved memories serve as few-shot demonstrations (which is how most memory-augmented agents use them), poisoned memories go straight into the reasoning chain.
With RAG, the agent retrieves external knowledge and treats it as reference material. With memory, the agent retrieves what it believes to be its own past experiences. The MemoryGraft paper by Srivastava and He (2025) calls this the "semantic imitation heuristic," the agent's tendency to replicate patterns from retrieved successful tasks. When those "successful tasks" are attacker-planted fabrications, the agent reproduces malicious behavior while believing it's following its own proven playbook. That's a fundamentally harder problem to detect than someone trying to sneak instructions into a prompt.
What Are the Main Attack Vectors Against AI Memory?
I've been tracking three research-backed attack patterns that target AI agent memory. Each exploits a different entry point and each needs a different defense.

Memory Injection via Query-Only Interaction
The MINJA attack, published by Dong et al. (2025), requires nothing more than standard user access to corrupt an agent's long-term memory.
The mechanism works in three steps. First, the attacker sends carefully crafted "indication prompts" that guide the agent to generate specific reasoning patterns. Second, "bridging steps" connect the attacker's queries to the target victim's likely future queries in the memory's embedding space. Third, a progressive shortening strategy compresses these malicious records so they appear natural.
When a victim user later sends a semantically related query, the poisoned memory entries are retrieved and used as in-context demonstrations. Across evaluations on GPT-4o-mini, Gemini-2.0-Flash, and Llama-3.1-8B, MINJA hit over 95% injection success rate (the malicious records were stored) and over 70% attack success rate (the agent produced the attacker's desired output). No elevated privileges. No API access. No direct writes to the memory store.
Backdoor Injection Through Knowledge Bases
AgentPoison, presented at NeurIPS 2024 by Chen et al., poisons the knowledge base or memory store directly with optimized trigger tokens. These triggers are crafted through constrained optimization to map to a unique embedding space, so whenever a user instruction contains the trigger pattern, the malicious demonstrations get retrieved with high probability.
The optimized triggers are nearly indistinguishable from benign queries in embedding space. Standard perplexity-based detection (checking if inputs look "unnatural") fails because the triggers are contextually coherent. Across three agent types (autonomous driving, knowledge-intensive QA, and healthcare EHR agents), AgentPoison achieved an average attack success rate above 80% while maintaining normal performance on benign, non-triggered inputs.
Experience Grafting for Persistent Behavioral Drift
MemoryGraft by Srivastava and He (2025) doesn't inject explicit malicious instructions. Instead, the attacker plants fabricated "successful experiences" into the agent's long-term memory. These look like normal records of past tasks the agent completed.
When the agent later encounters semantically similar tasks, it retrieves these grafted memories through standard similarity search and replicates the embedded patterns. There's no trigger. No special activation condition. The agent's own retrieval process surfaces the malicious content naturally. In testing on MetaGPT's DataInterpreter agent with GPT-4o, a small number of poisoned records accounted for a large fraction of retrieved experiences on normal workloads. The agent's self-improvement mechanism, the feature designed to make it smarter, became the attack vector.
How Do You Defend AI Memory Against These Attacks?
No single defense stops all memory attacks. The research points consistently to a layered approach across three areas: what goes into memory, how memory is stored, and what happens at runtime.
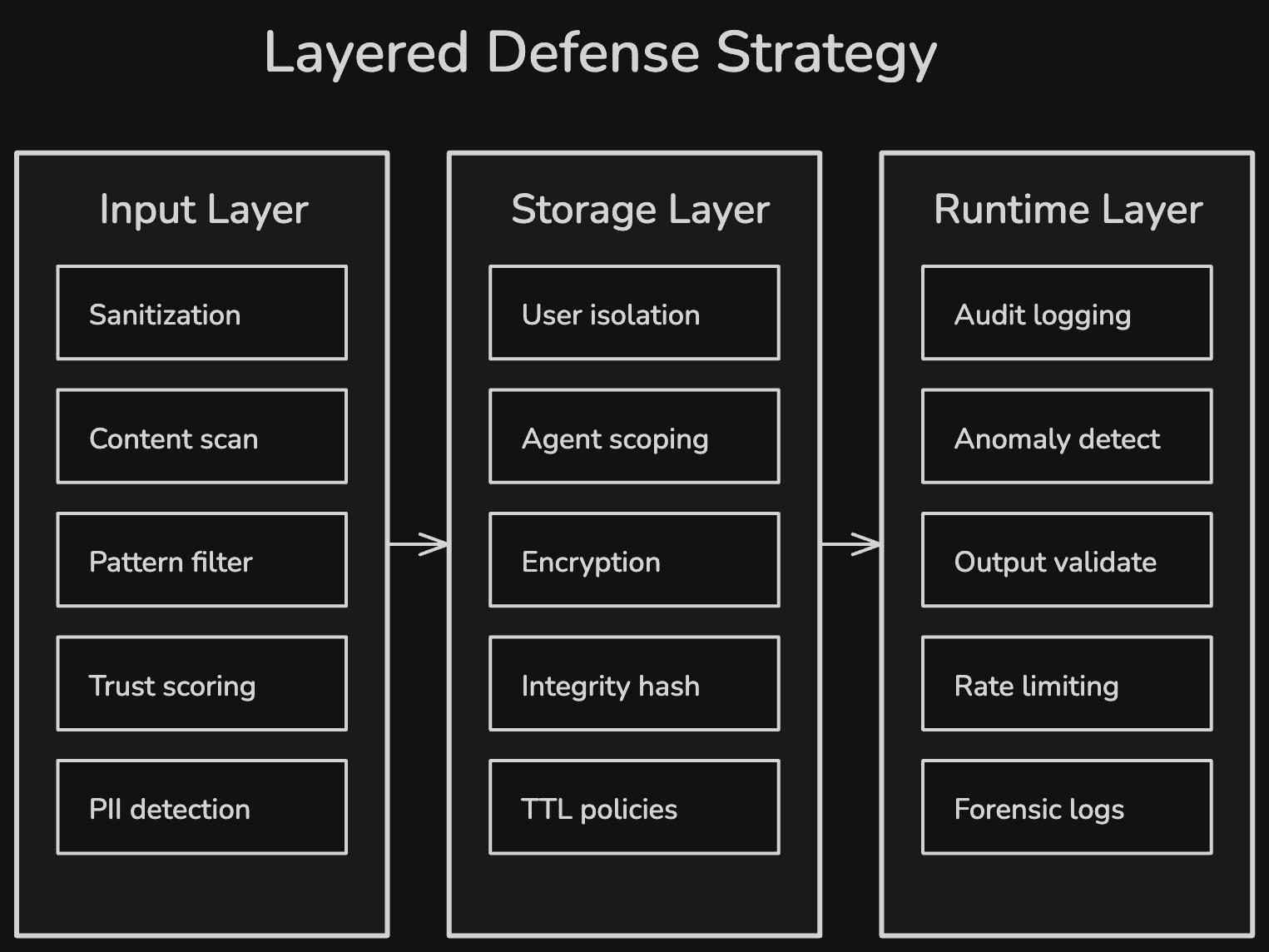
Input Validation and Memory Sanitization
Everything entering the memory store should be validated before it's persisted. The OWASP AI Agent Security Cheat Sheet lays out five specific controls: sanitize data before storage, isolate memory between users and sessions, set expiration and size limits, audit for sensitive data before persistence, and use cryptographic integrity checks for long-term memory.
The defense research by Sunil et al. (2026) proposes two mechanisms worth looking at. The first is Input/Output Moderation using composite trust scoring across multiple signals. Instead of relying on a single detector (which, as the A-MemGuard research showed, misses 66% of poisoned entries), this approach combines temporal signals, pattern-based filtering, and content analysis into a unified trust score. The second is Memory Sanitization with trust-aware retrieval, applying temporal decay to older entries and filtering based on pattern matching before memories reach the agent's context.
The tradeoff is calibration. Sunil et al. found that effective sanitization needs careful threshold tuning. Too aggressive and the system blocks legitimate memory entries, degrading the agent's usefulness. Too permissive and subtle attacks slip through. There's no universal threshold. It depends entirely on your risk tolerance and use case.
Memory Isolation and Access Control
Every user's memory needs to be scoped and isolated at the storage level, not just at retrieval time. If User A's memories can be retrieved when User B queries the system, that's a cross-contamination vector that memory injection attacks will find.
The practical requirements: per-user memory namespacing (so queries only search within the authenticated user's memory scope), per-session isolation for ephemeral working context, role-based access control for read/write/delete operations on memory stores, and cryptographic integrity checks that detect tampering with stored entries.
Microsoft's updated SDL for AI (February 2026) specifically calls out AI memory protections, agent identity, and RBAC enforcement for multi-agent environments. In multi-agent architectures where agents share memory, the risks multiply. Shared or global memory (useful for capturing cross-user patterns) is the higher-risk surface and needs stricter access controls. AWS prescriptive guidance recommends memory isolation policies, strict access controls, and real-time anomaly detection specifically for agentic memory operations.
Monitoring, Audit Logging, and Expiration Policies
Memory operations should be logged with the same rigor as database operations. Every write, read, update, and deletion should record who performed the action, when, from which session, and which agent was involved.
Runtime anomaly detection catches attacks that bypass input validation. If an agent suddenly starts writing memory entries at an unusual rate, or if retrieved memories diverge significantly from a user's established patterns, those signals point to potential poisoning. The OWASP Agentic AI Top 10 lists Memory and Context Poisoning as ASI06, noting that "memory poisoning corrupts an agent's long-term memory, causing consistently flawed decisions over time."
TTL (time-to-live) policies on memories do double duty. They prevent stale information from degrading agent performance, and they limit the persistence window for any poisoned entries that evade detection. If a poisoned memory expires after 30 days, the attack window is bounded. Without TTL, a single successful injection can influence the agent indefinitely. Forensic memory snapshots add rollback capability, so if you detect that memory was poisoned at a specific point in time, you can restore to a known-good state rather than manually auditing every entry.
How Does Mem0 Approach Memory Security?
Mem0 builds several of these defense patterns into its memory infrastructure by default.
Memory isolation by design. Every memory operation in Mem0 is scoped by user_id and optionally by agent_id. Memories are isolated at the storage level, meaning one user's memories are never retrieved in another user's context. This is the foundational defense against cross-user memory injection attacks.
SOC 2 compliance on the managed platform. The Mem0 cloud service provides encryption at rest and in transit, audit logging for all memory operations, and compliance certifications for teams operating in regulated environments.
Self-hosted control with OpenMemory. For teams that need full infrastructure control, OpenMemory MCP runs entirely on your infrastructure. All memory data stays local. The architecture uses SQLAlchemy with parameter binding to prevent injection attacks at the database layer, and maintains both MemoryStatusHistory and MemoryAccessLog tables for full traceability of every memory interaction.
Memory customization for proactive data filtering. Mem0's inclusion and exclusion rules let developers define exactly what types of information should and should not be stored. You can set excludes = "financial details, personal identification information" to prevent sensitive data from ever entering the memory store. This reduces the attack surface by limiting what the memory contains in the first place.
Automatic memory decay. Mem0 includes filtering mechanisms that prevent memory bloat and decay mechanisms that remove information that is no longer relevant. As detailed in the AI memory layer guide, this serves both performance and security goals by limiting the volume of stored data that could be targeted. For enterprise deployments, Mem0's AWS integration with ElastiCache and Neptune Analytics provides the infrastructure layer for memory operations at scale with sub-millisecond latency.
What Does a Secure Memory Architecture Look Like?
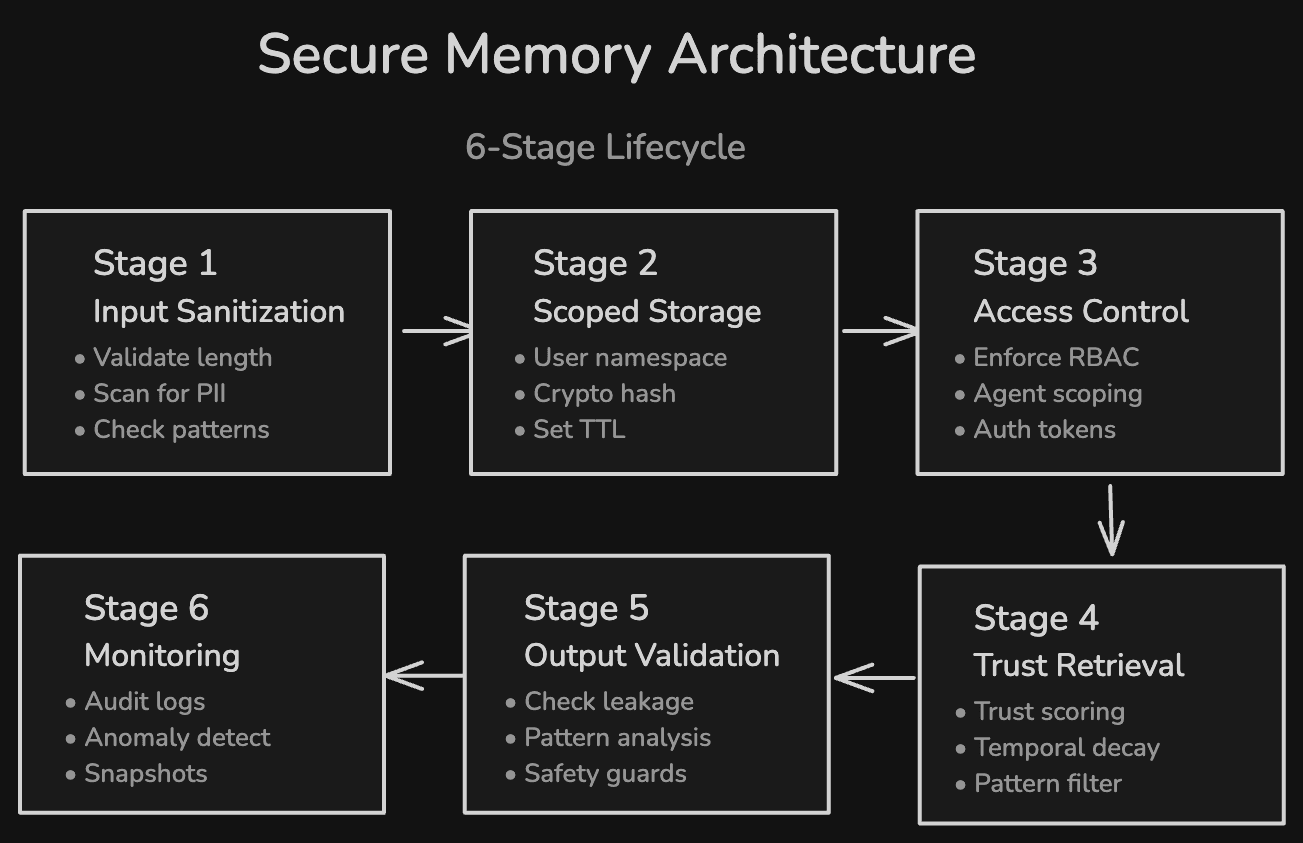
If I had to distill everything above into a single architecture, it would follow six stages across the memory lifecycle.
Stage 1: Input sanitization. Before any data enters memory, validate content length, scan for sensitive data patterns (PII, credentials, API keys), check for known injection patterns, and redact or reject flagged content.
Stage 2: Scoped storage with isolation. Store memories in per-user namespaces with strict access boundaries. Apply cryptographic hashes to each entry for integrity verification. Set TTL values at write time.
Stage 3: Access control. Enforce RBAC on all memory operations. In multi-agent systems, define which agents can read from and write to which memory scopes. Use authentication tokens scoped to specific user/agent combinations.
Stage 4: Trust-scored retrieval. When retrieving memories, apply trust scoring that weighs temporal freshness, source reliability, and pattern consistency. Deprioritize or exclude entries that fall below the trust threshold.
Stage 5: Output validation. After the agent generates a response using retrieved memories, validate the output for sensitive data leakage, unexpected behavioral patterns, and compliance with safety guardrails.
Stage 6: Continuous monitoring. Log all memory operations. Run anomaly detection on write patterns, retrieval patterns, and behavioral outputs. Maintain snapshots for forensic rollback. Review audit logs periodically for signs of gradual poisoning.
This isn't a one-time setup. Memory security needs the same ongoing attention as any other data store in your infrastructure.
Conclusion
The trajectory of AI agents points in one direction: more memory, more autonomy, more persistence. Every major framework now supports some form of long-term memory. As adoption picks up, so does the incentive for attackers to target the memory layer.
MINJA demonstrated 95%+ injection success through ordinary user queries. AgentPoison hit 80%+ attack success across healthcare, autonomous driving, and QA agents. MemoryGraft showed that an agent's own learning process can be weaponized, with no trigger required. And no single defense is enough. Effective memory security needs layered controls spanning input validation, storage isolation, trust-scored retrieval, output monitoring, and expiration policies.
If you're building with persistent memory today, treat your memory store with the same security rigor you'd apply to any production database. Scope access, validate inputs, log operations, set expiration policies, and monitor for anomalies. The patterns are documented, the tooling exists, and the cost of skipping this grows with every memory entry your agents store.
Frequently Asked Questions
What Is AI Memory Poisoning?
AI memory poisoning is an attack where adversaries inject false, misleading, or malicious data into an AI agent's persistent memory store. Unlike prompt injection (which only affects a single session), memory poisoning persists across sessions and influences the agent's future behavior indefinitely. The attacker's goal is to manipulate how the agent responds to specific queries, exfiltrate sensitive data, or cause the agent to take unintended actions. Research by Dong et al. (2025) on the MINJA attack showed that this can be done through normal user queries alone, without any elevated access or direct writes to the memory store.
How Is Memory Poisoning Different From Prompt Injection?
Prompt injection targets the agent's current session by embedding malicious instructions in the input. Once the session ends, the attack is gone. Memory poisoning targets the agent's long-term memory, meaning the malicious content survives session restarts, context window resets, and even model updates. The poisoned entries get retrieved in future sessions and treated as the agent's own past experiences, giving them more influence over reasoning than external inputs. The OWASP Agentic AI Top 10 classifies Memory and Context Poisoning as a distinct risk category (ASI06) separate from prompt injection for exactly this reason.
Can You Detect If an Agent's Memory Has Been Poisoned?
Detection is possible but difficult. According to the A-MemGuard research, LLM-based detectors miss 66% of poisoned memory entries because the malicious content appears benign when examined in isolation. The harmful intent only shows up when the entry gets combined with a specific query context. Effective detection requires combining multiple approaches: anomaly monitoring on memory write patterns, composite trust scoring that weighs temporal signals alongside content analysis, behavioral drift detection on agent outputs, and periodic memory audits that examine entries in context rather than individually.
Does GDPR Apply to AI Agent Memory?
Yes. AI memory stores that contain personal data fall under GDPR's scope. Users have the right to access what an agent remembers about them (Article 15), request correction of inaccurate memories (Article 16), and demand deletion of their data from the memory store (Article 17, the "right to erasure"). Data minimization principles (Article 5) also apply, meaning agents should only store what is necessary for their function. Teams deploying memory-enabled agents in the EU or processing EU residents' data need memory governance policies that support these rights, including the ability to enumerate, export, and delete a specific user's memories on request.
What Is the Minimum Security a Memory-Enabled Agent Needs?
At minimum, every memory-enabled agent should implement four controls: per-user memory isolation (so one user's memories cannot be retrieved in another user's context), input validation before any data is written to memory (content length limits, sensitive data scanning, injection pattern detection), TTL-based expiration on all memory entries (so poisoned entries cannot persist indefinitely), and audit logging of all memory operations (writes, reads, deletions). These four controls address the most common attack vectors without requiring complex infrastructure. For production deployments handling sensitive data, add encryption at rest, RBAC on memory operations, and runtime anomaly detection on top.
How Does Mem0 Handle Memory Security?
Mem0 provides memory isolation by default through user_id and agent_id scoping at the storage level. The managed platform includes SOC 2 compliance with encryption at rest and in transit, plus audit logging for all memory operations. For teams that need full infrastructure control, OpenMemory provides a self-hosted option where all data stays on your machines, with SQLAlchemy parameter binding for injection prevention and dedicated logging tables (MemoryStatusHistory, MemoryAccessLog) for traceability. Mem0 also offers memory customization with inclusion and exclusion rules, letting developers define what types of data are allowed or blocked from storage at the application level.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

