



Memory vs Context Window: Why Most AI Agents Fail
Your agent isn't forgetting because the model is dumb. It's forgetting because you're using RAM like a hard drive.
There is a failure mode that nearly every builder hits somewhere between week two and month two of running an agent in production. The agent is mid-task, eight or ten tool calls deep, and it contradicts a decision it made four steps ago, re-fetches data it already retrieved, or ignores a constraint the user gave at the start of the session. Here, the model has not changed, and the prompts have not changed, yet the agent just stopped holding its context together.
The instinctive diagnosis is that the model forgot. The real diagnosis is simpler and more actionable:
The architecture treats the context window as a database, but the context window is not a database.
It behaves like RAM, and when you build against it as if it were storage, you get failures that look like model problems but are not.
This explains why most production agent failures are not model failures but memory architecture failures, and it points us to build a separate persistent memory layer and manage the context window the way an operating system manages RAM, being in control of what goes in, what stays, and what gets evicted.
This article explains why the analogy holds, what breaks when the two layers are confused, and what the design patterns look like, that get it right in production.
Why Context Window Behaves Like RAM?
The context window shares three properties with RAM that distinguish it from persistent storage and make it unsuitable as a long-term data store:
Volatile: Everything in the context window disappears when the session ends, including preferences stated at turn 1, constraints set at turn 3, and decisions made at turn 7. Persistent storage survives process boundaries, but the context window does not.
Degrades under load: Performance degrades well before the token limit is reached. The "lost in the middle" effect documented by Liu et al. in their 2023 paper shows that LLMs retrieve information from the beginning and end of context reliably, but information buried in the middle receives significantly less attention.
Expensive per access: Keeping irrelevant data in the context window wastes compute and budget on every inference. Every LLM call re-processes the entire context window, meaning a 50,000-token context does not cost less than a 10,000-token context just because only the last 500 tokens changed.
Here is a table that makes the structural differences precise:
Property | Context Window | Computer RAM | Persistent Storage |
|---|---|---|---|
Volatility | Clears at session end | Clears at the process end | Survives indefinitely |
Capacity effect | Degrades before full | Binary: has capacity or does not | Scales with hardware |
Access cost | Full re-read every call | Direct address lookup | Seek and read overhead |
Update mechanism | Append only | Random write | Read-modify-write |
Failure mode | Burial and attention dilution | Overflow crash | Corruption or loss |
Best for | Active reasoning and recent context | Running computation | Facts, preferences, history |
The context window is good at holding the active working state of the current task. Using it for long-term facts, cross-session preferences, or hard constraints produces the failure modes that look like model problems but are not.
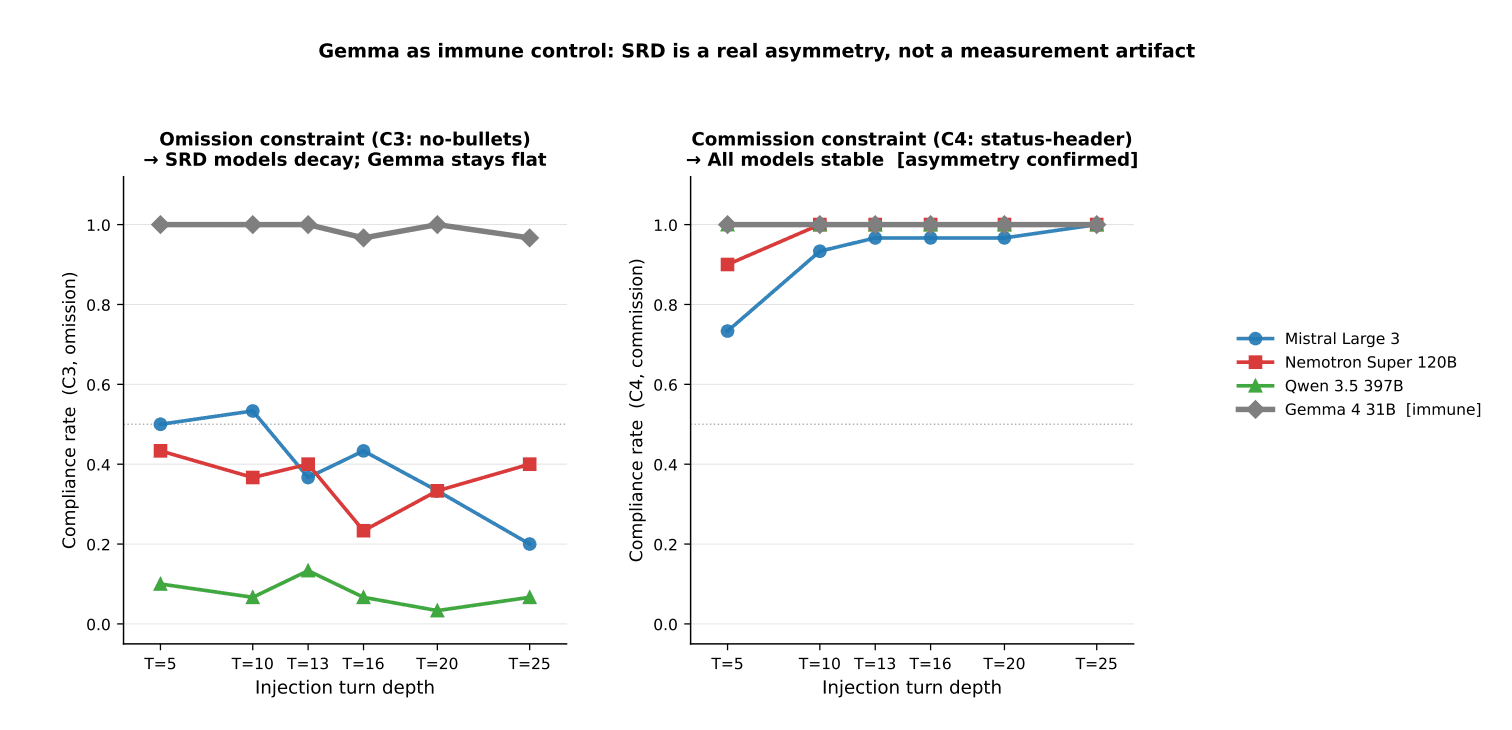
Fig: Commission constraints hold near 100% while omission constraints decay with depth in susceptible models (Source)
The April 2026 study "Omission Constraints Decay While Commission Constraints Persist in Long-Context LLM Agents" by Yeran Gamage quantifies this across 4,416 trials at six conversation depths. If your agent violates a constraint it followed correctly 10 turns ago, the model did not change. The attention weight on that constraint dropped below the threshold required to enforce it. That is a memory architecture problem, not a model problem.
Key insight: If your agent violates a constraint it followed correctly 10 turns ago, the model did not change. The attention weight on that constraint dropped below the threshold required to enforce it. That is a memory architecture problem, not a model problem.
Two Memory Layers
Every piece of information an agent encounters belongs in one of two places, and the distinction follows directly from the structural properties described above.
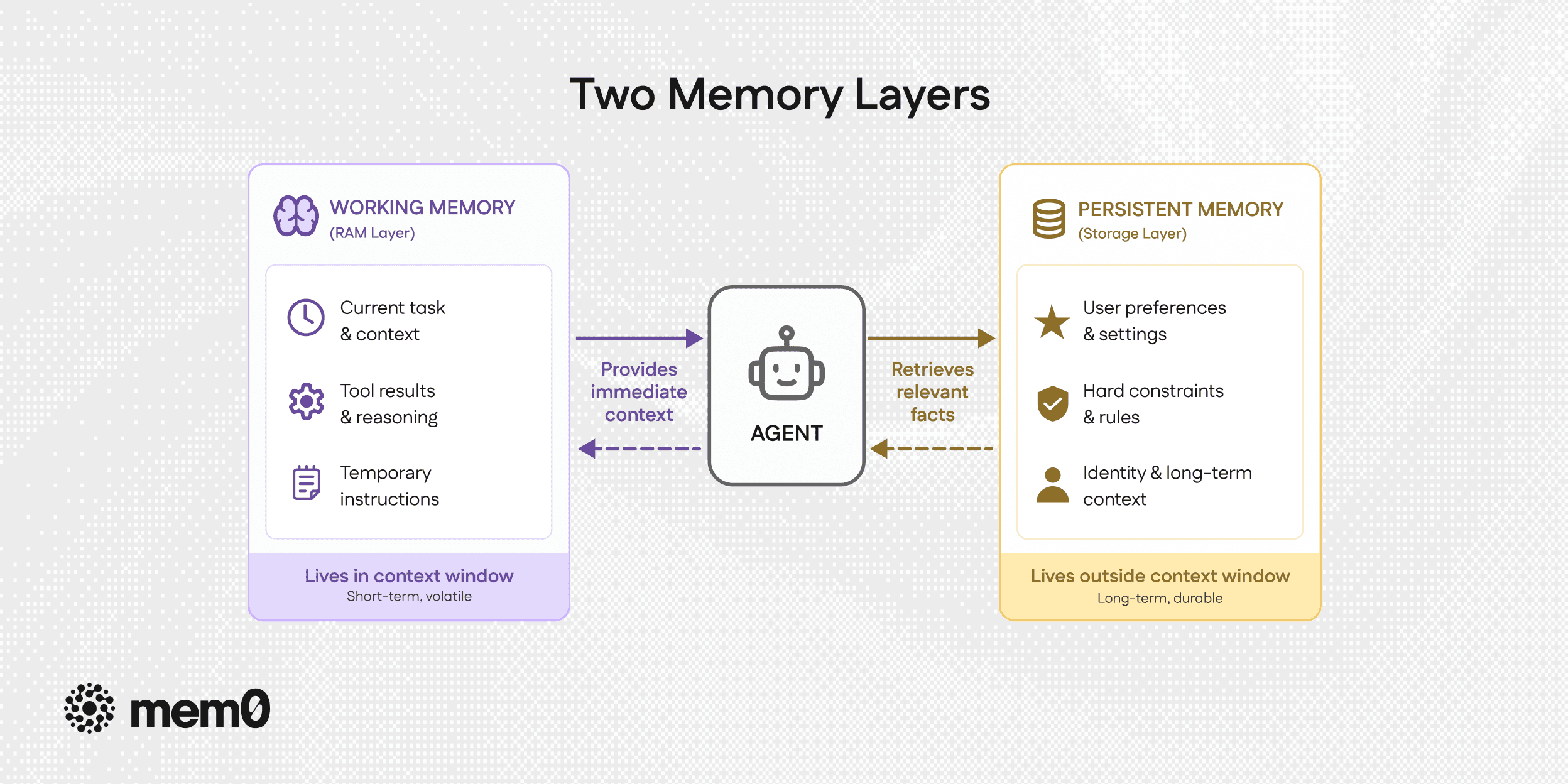
Fig: Two memory layers
Working Memory: RAM Layer
Working memory holds everything the agent needs to complete the current task and nothing else. It lives in the context window because it needs to be immediately accessible on every call, changes rapidly during task execution, and does not need to survive the session.
What belongs in working memory:
The current task description and the user's immediate request
Intermediate tool results, compressed to their relevant facts
The active reasoning trace covering what the agent has decided and what comes next
Mid-task instructions that modify the current task
Temporary constraints that apply only to this session or task
What does not belong in working memory:
Stable user preferences, such as lighting temperature or coding style
Hard constraints that must be enforced across all sessions
Identity facts such as timezone, language, and professional context
Historical context from previous sessions
Tool results from tasks that are already complete
The key property of working memory is that it should be actively managed. This means that the content is added when needed and removed when the task that required it is done. An agent that appends every tool result to its context window without ever removing anything is filling RAM with data it no longer needs, causing the burial zone to grow until early instructions lose ground to later noise.
Persistent Memory: Storage Layer
Persistent memory holds everything that needs to survive session boundaries and be retrievable in future sessions. It lives outside the context window in a vector store, a structured database, or a dedicated memory service like Mem0, because it needs to survive process termination and scale beyond what any context window can hold.
What belongs in persistent memory:
Stable user preferences with exact values
Hard constraints that must never be violated
Behavioural patterns observed across multiple sessions
Identity facts and long-horizon context
Task state that needs to survive session boundaries
What does not belong in persistent memory:
Session-only modifiers
Raw tool results from completed tasks
Speculative inferences from a single session
Intermediate reasoning steps from tasks that are already complete
Dimension | Working Memory (RAM layer) | Persistent Memory (Storage layer) |
|---|---|---|
Lifetime | Current task or session | Indefinitely or until TTL expires |
Retrieval | Full context on every LLM call | Semantic search, top-K relevant facts |
Update pattern | Append during task, clear at close | Extract stable facts, write explicitly |
Failure mode | Burial, dilution, instruction loss | Staleness, over-persistence, and extraction errors |
Token cost | Scales with task depth | Fixed retrieval budget, typically 5 to 10 facts |
Example content | "Step 3 result: found 4 matches." | "User prefers Python with type hints." |
Routing Decision
But how do we decide where new information belongs? Here is a question that routes this decision for us:
Would this still be relevant in 30 days?
If yes, it belongs in persistent memory. If no, the follow-up question is whether it needs to survive the current session boundary. Task state with a TTL goes to a task store, and session-only modifiers stay in working memory only. The classification happens at ingestion time, not at retrieval time, so the system never has to guess later.
Four Failure Modes When the Layers Are Mixed
Most production agent failures trace back to one of four specific ways the two layers get conflated.
1. Token Bloat and Cost Explosion
When every tool result and intermediate step is appended to the context window without eviction, the token cost per call grows linearly with session length. A session starting at 2,000 tokens can balloon to over 25,000 tokens as the conversation progresses, leading to high cost and latency penalties.
The 2026 LoCoMo benchmark updates from Mem0’s latest research demonstrate a new frontier for memory efficiency:
Full-context (Baseline): 72.9% accuracy, ~26,000+ tokens, p95 latency 17.12 seconds.
Mem0 (New Algorithm): 91.6% accuracy, <7,000 tokens (mean), p95 latency ~1.44 seconds.
By moving to a single-pass hierarchical extraction and multi-signal retrieval pipeline, Mem0 outperformed the original full-context baseline by 18.7 percentage points while still maintaining a 4x reduction in token cost and a 91% reduction in latency.
2. Preference Dilution and Safety Rule Violations
When stable preferences and hard constraints live in conversation history rather than pinned to the system prompt, they are subject to the same positional attention decay as everything else. A constraint set at turn 3 that has not been exercised by turn 16 has a 33% compliance rate according to the Gamage study, compared to 73% at turn 5. The fix is constraint pinning, i.e., retrieve from persistent memory on every call and inject at the top of the system prompt, where burial is structurally impossible.
3. Contradictory Behaviour Mid-Session
When working memory accumulates without management, the agent can hold contradictory signals simultaneously, such that a user who says "keep the report concise" at turn 3 may find the agent producing verbose output at turn 8 after a tool result returned a long document, because the instruction is buried under several thousand tokens of content that arrived after it. The Gamage study documents this as a passive decay process rather than an adversarial attack, meaning the agent is simply attending to recent content more reliably than early content as the session grows.
4. Inconsistent Behaviour Across Sessions
When preferences are stored as raw conversation history rather than extracted to a persistent store, exact values disappear when compression fires. "User wants 2700K warm white lighting after 8 pm" becomes "user has lighting preferences," and the agent becomes correctly general and usefully precise at different points in the same session, depending entirely on whether the preference predates the last compression pass, producing behavior that is impossible to debug without understanding the compression schedule.
Five Design Patterns That Fix This
The following patterns address each failure mode and are framework-agnostic, applying whether the agent is built on LangGraph, Hermes, CrewAI, or a custom stack.
1. Hard Constraint Pinning
Hard constraints are retrieved from persistent memory on every LLM call and injected at the top of the system prompt before any conversation history, so that position cannot affect them regardless of session depth.
2. Tool Result Summarization Before Injection
Raw tool results are summarized to their relevant facts before entering working memory, so a 2,000-token API response becomes a 100-token fact summary. Over ten tool calls, the working memory footprint drops from roughly 20,000 tokens to approximately 1,000 tokens for the same information content.
3. Active Modifier Re-injection
Mid-task instructions are stored in a working memory object and re-injected into the system prompt on every subsequent call until the task completes, rather than being left in conversation history to compete for attention.
4. Session-Close Extraction
When a session ends, a single extraction pass writes stable preferences to persistent memory and discards everything else. This is the only point where working memory observations graduate to persistent storage.
5. Structured Compression with External Memory
For agents using Hermes, the ContextCompressor fires at 50% of the model's context window and performs a lossy summarization pass that preserves narrative coherence but can drop exact values from preferences seeded early in the session. The combination that works in production is to let Hermes manage within-session compression for narrative continuity and use an external persistent store to preserve exact-value preferences and hard constraints that must survive compression passes.
Hence, two systems complement rather than compete. Hermes handles the working memory layer and the external store, like Mem0, and handles the persistent memory layer.
What to Measure
Testing agent memory correctly requires distinguishing between within-session and cross-session failures because they have different causes and different fixes.
Within-session metrics:
Constraint Adherence Rate by Turn Depth: Measure at turns 5, 10, 15, and 20 for any constraint set at turn 1. The Gamage study baseline is 73% at turn 5, falling to 33% at turn 16 without mitigation, and with constraint pinning adherence should hold above 90% at all measured depths.
Exact Value Accuracy: Keyword-based scoring catches whether the agent addressed a preference category, but strict value scoring checks whether it used the correct specific value, such as 2700K rather than "warm lighting." The two scores diverge significantly under burial conditions where the agent remembers the category but has lost the exact value.
Working Memory Token Footprint Over Time: Track prompt tokens per call across a 20-turn session. A flat or slowly growing line indicates healthy working memory management, and an exponentially growing line indicates accumulation without eviction.
Cross-session metrics:
Preference Persistence Rate: State a preference explicitly in session 1 and check for it at the start of session 2 without restating it. If the agent does not apply it correctly, the session-close extraction is failing.
Constraint Survival After Compression: State a hard constraint early in a session, allow compression to fire, and then trigger the constraint late in the same session. With pinning, adherence should be unaffected by compression, and without pinning, it degrades exactly as the Gamage study predicts.
The LoCoMo benchmark provides a standardized evaluation set for cross-session memory quality if a comparison against published baselines is needed.
Conclusion
The context window is RAM because it is fast, immediately accessible to the model on every call, and structurally unsuited for anything that needs to survive beyond the current task. Treating it as persistent storage by appending every fact, every preference, every tool result, and every constraint to the conversation history and expecting the model to hold it all reliably across dozens of tool calls is asking RAM to do the job of a database, and the failures that result are predictable and reproducible.
The production agents that hold together across hundreds of tool calls and dozens of sessions are not running better models but cleaner memory architectures:
A tightly managed working memory layer that holds only what the current task needs
A persistent memory layer that holds what the agent needs to know across sessions
Hard constraints are pinned at the system level so that position cannot affect them
Tool results are summarized before injection, so working memory stays lean
Mid-task instructions are re-injected explicitly so they cannot be buried
Session closes that extracts what is worth keeping before the RAM is cleared
All of the above requires understanding which of the two layers each piece of information belongs to and building the architecture around that distinction from the start, rather than discovering it in production.
Frequently Asked Questions
Q: Does a larger context window solve this? No. The lost-in-the-middle effect means performance degrades before the limit is reached. A 1M-token context window does not prevent attention dilution; it just delays it and makes every inference more expensive.
Q: How do I know if my agent has this problem? Run a 20-turn session with a hard constraint seeded at turn 1. Check compliance at turns 10, 15, and 20. If compliance drops, you have an architecture problem. The fix is constraint pinning.
Q: Is Mem0 the only way to implement the persistent memory layer? No. Any durable store works, including a PostgreSQL table with embeddings, a vector database, or a file-based store for simple use cases. Mem0 handles extraction, deduplication, and retrieval automatically, but the patterns in this article work with any persistent store.
Q: What about within-session working memory for coding agents? The same principles apply. Coding agents accumulate tool results from file reads, test runs, and linter output across many calls. Summarize each result before injection and pin style constraints from persistent memory on every call.
References:
Liu et al., "Lost in the Middle: How Language Models Use Long Contexts" (2023)
Gamage, "Omission Constraints Decay While Commission Constraints Persist in Long-Context LLM Agents" (April 2026)
Lumer et al., "MemTool: Optimizing Short-Term Memory Management for Dynamic Tool Calling in LLM Agent Multi-Turn Conversations" (July 2025)
Chhikara et al., "Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory" (April 2025)
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

