



Loop engineering is the practice of designing, implementing, and tuning the control loop that governs how an AI agent interacts with its environment over time. It focuses on how the agent reads context, plans, acts, observes results, and updates its internal state across many steps.
Most LLM workflows were originally designed as single-shot prompts. Production agents, however, run for hundreds or thousands of steps, often across multiple sessions and users. Loop engineering is about making those long-running loops reliable, efficient, and aligned with the product’s goals.
A core challenge inside any loop is memory. Agents need to remember what happened before, what the user prefers, and what has already been tried. That is where a structured memory layer such as Mem0 changes the shape of the loop.
Token-Rich vs Token-Poor Loops
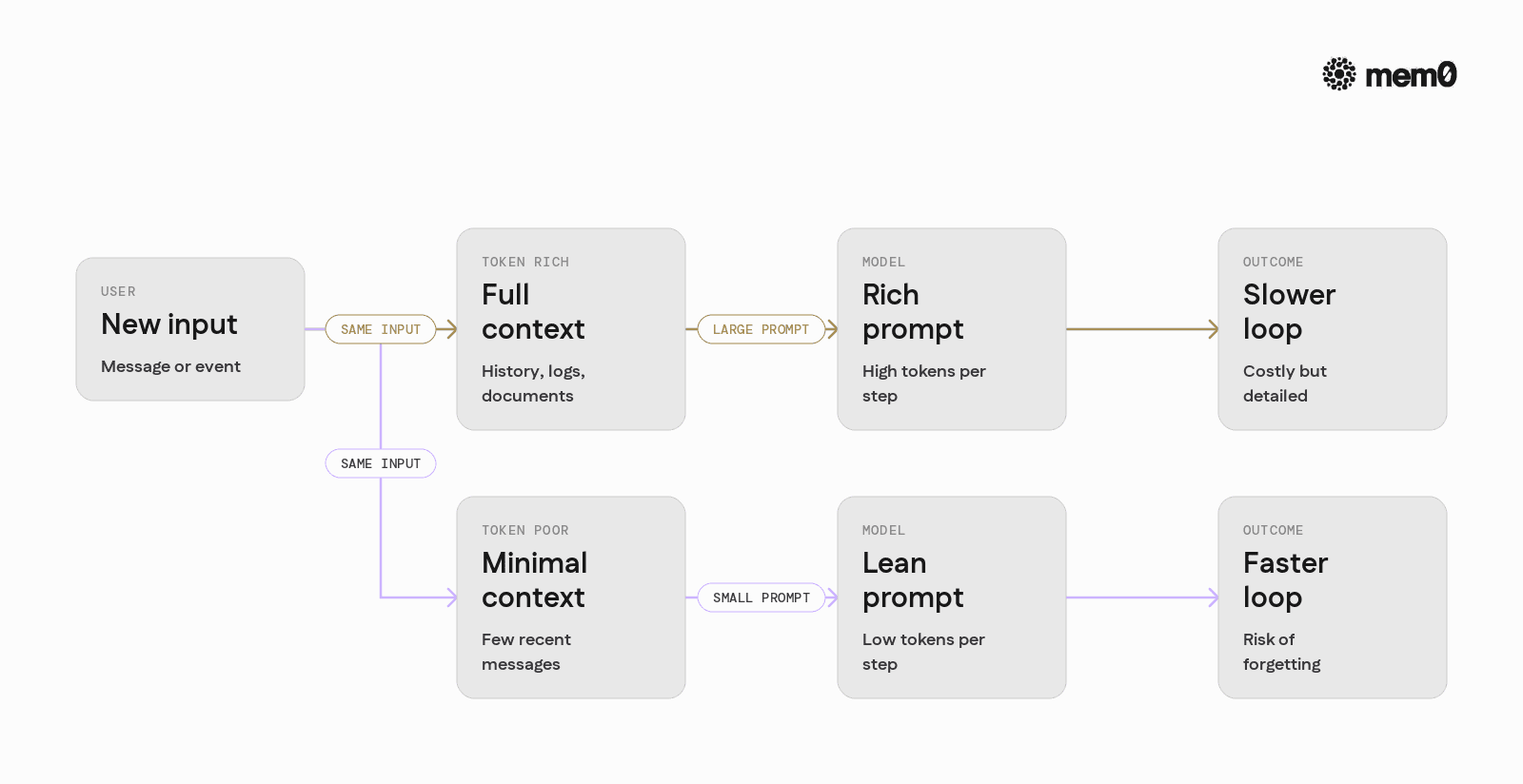
Loop engineering usually starts with one design choice. How much context should the model see at each step?
Token-rich loops
A token-rich loop is one where each iteration includes a large amount of context in the prompt. Examples:
Full conversation transcripts
Detailed tool call logs
Long documents or codebases
Embedded plans and subgoals
Pros:
The model has a high-resolution view of history
Fewer mistakes due to missing context
Simpler reasoning about what the model "knows"
Cons:
High token cost per step
Slow responses
Risk of context window overflow
Harder to scale to many users or long sessions
Token-poor loops
A token-poor loop is one where each iteration includes minimal context. For example:
Only the last 2-3 messages
Short summaries instead of raw logs
A few retrieved memories instead of full history
Pros:
Lower token usage
Faster response times
Easier to stay within context limits
Cons:
More hallucinations and repeated work
Higher risk of the agent forgetting important details
Requires better memory and summarization infrastructure
Loop engineering is the art of finding a balance between token-rich and token-poor, driven by latency, cost, quality, and safety requirements.
Why Developers Should Care About Loop Engineering?
Loop design directly affects:
Reliability: Does the agent forget crucial user constraints halfway through a workflow?
Cost: Are you paying for thousands of irrelevant tokens per request?
Latency: Does the user wait 10 seconds for every response because the prompt is massive?
Safety: Does the agent have the right historical context to avoid harmful or inconsistent actions?
In practice, many teams start with a token-rich approach because it is easy. Everything goes into the context window. Over time, they discover:
The model still forgets due to truncation at the head of the context
Billing grows significantly as usage scales
There is no clear structure around what the agent should remember
At this point, loop engineering becomes a priority, and building or adopting a memory system becomes critical.
What People Mean by Loop Engineering Today?
In current AI engineering discussions, "loop engineering" is used to describe several related practices:
Control flow design
How to structure perception, planning, action, and feedback. For example:ReAct-style loops
Planning with subgoals
Tool-using agents with retriable steps
Context management
The policies for what goes into the prompt each step:Sliding windows over chat history
Summaries instead of raw logs
Retrieval-augmented context
State and memory design
How the agent stores and reuses information across steps and sessions:Persistent user profiles
Long-term task state
Learned preferences and constraints
Evaluation and feedback loops
How the system monitors behavior and adjusts:Self-critique prompts
External evaluators
Metrics-driven loop tuning
In all of these, memory is both a design primitive and a bottleneck. Without explicit memory, loop engineering devolves into substring management inside a single context window.
Core Components of an Agent Loop
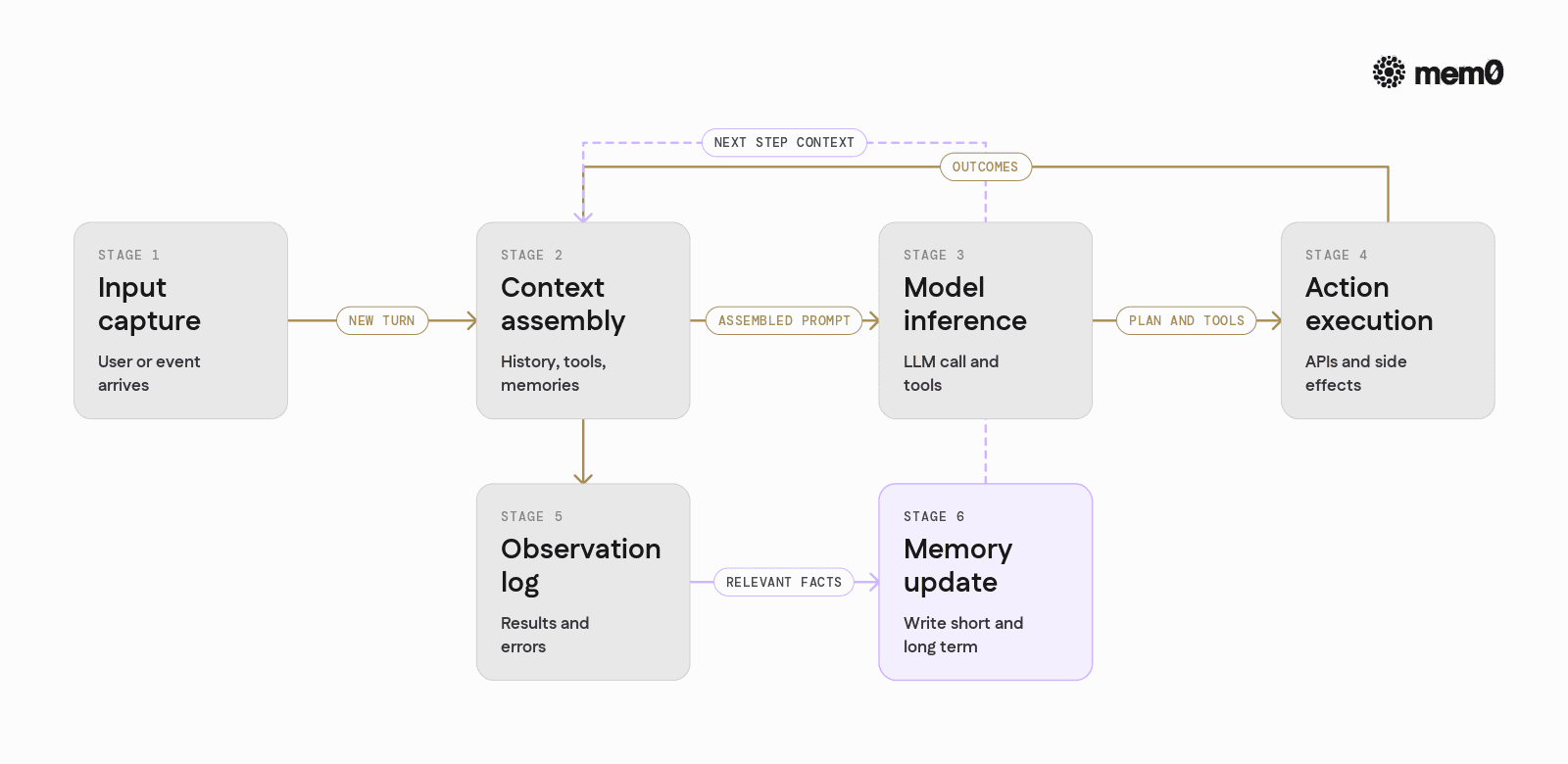
At a high level, a production agent loop involves the following stages:
Input capture
User message or environment event
Metadata such as user id, time, channel
Context assembly
Recent interaction history
Retrieved long-term memories
System instructions and tools
Task-specific context
Model inference
LLM call with assembled prompt
Optional function/tool call detection
Action execution
Tool calls, API requests, database operations
Effects applied to external systems
Observation and logging
Outcome of actions
Errors or exceptions
Relevant details for future decisions
Memory update
Decide what should be stored
Write to short-term and long-term memory
Possibly summarize or compress
Loop engineering is the process of making these stages explicit and tunable, instead of letting them emerge implicitly through a single long prompt.
The Memory Problem Inside Loops
Without a proper memory layer, agents tend to:
Re-ask users the same questions
Lose track of long-running tasks
Forget preferences and constraints
Repeat failed strategies
Produce inconsistent responses across sessions
Common ad-hoc solutions include:
Pushing entire chat logs into the prompt
Storing everything in a vector database and retrieving by similarity
Hand-written summaries for specific workflows
These approaches help but leave several gaps:
No structured notion of "user-level" versus "task-level" memories
No automatic decision about what to store or retrieve
No permissions or ownership model for memories
Hard to swap models or adjust loop design without rewriting memory code
This is the exact problem space Mem0 is designed to address.
How Mem0 Fits Into Loop Engineering
Mem0 provides an intelligent memory layer that slots directly into the loop, handling:
What to store: It can extract meaningful memories from raw text, tool outputs, and events.
How to store: It manages embeddings, metadata, and schemas internally.
What to retrieve: It can search, filter, and rank memories given the current context.
Across what scope: It supports user-level, agent-level, and global memories.
An agent loop with Mem0 roughly follows this pattern:
Receive user input.
Query Mem0 for relevant memories for this user and task.
Assemble prompt with: system instructions, tools, retrieved memories, recent interactions, and user message.
Call the LLM and execute any actions.
Send outputs and selected events back to Mem0 to update memory.
By moving memory into a dedicated layer, the loop becomes more token-efficient and easier to reason about. The agent does not need the entire raw history, it only needs the distilled memory that Mem0 returns.
Example: Token-Poor Loop with Mem0 in Python
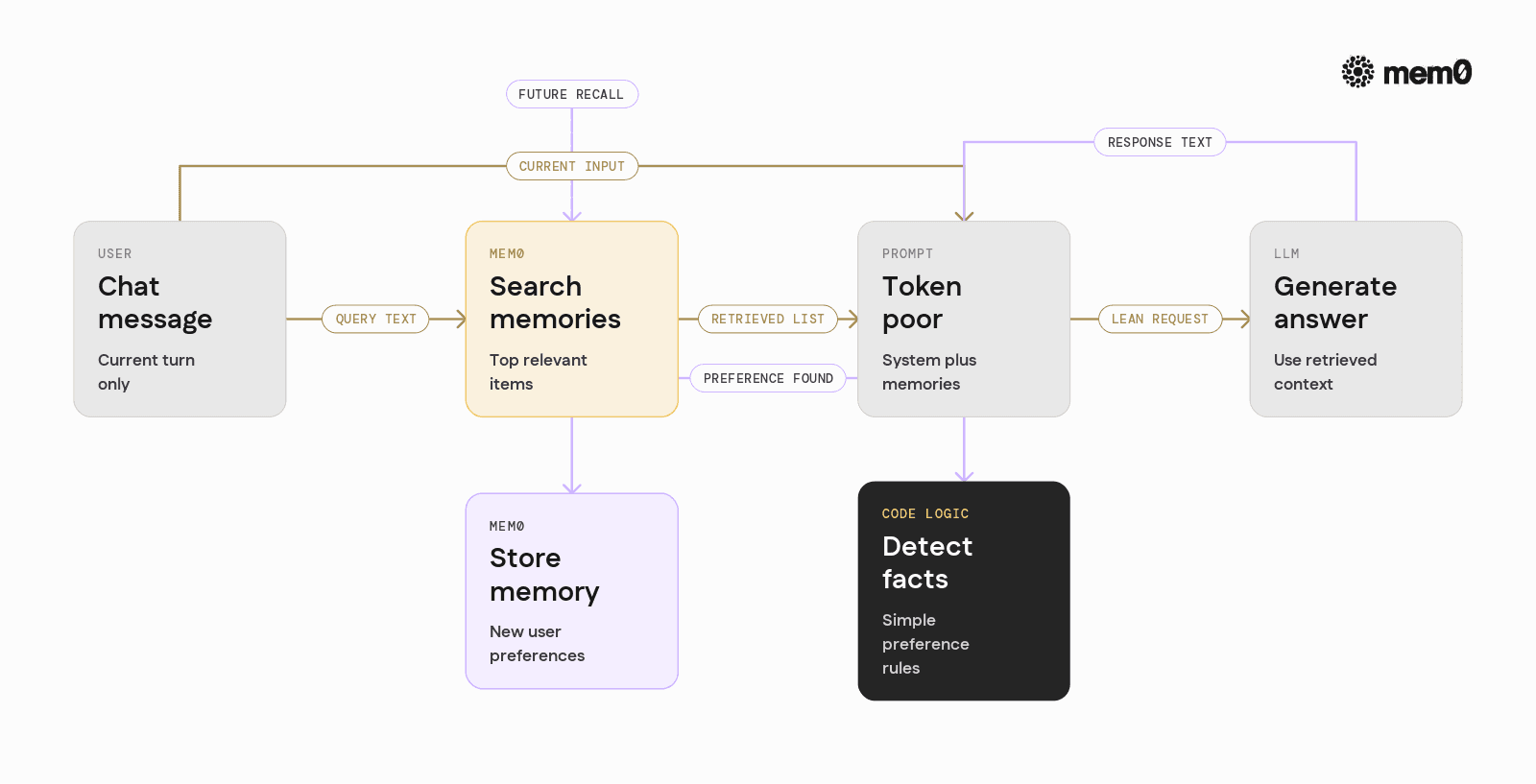
The following example shows a simple conversational agent that uses Mem0 to maintain long-term user memory while keeping each prompt token-poor.
Install dependencies first:
Then create a Python script:
This loop is explicitly token-poor:
It does not pass the entire conversation history
It retrieves only a small set of relevant memories from Mem0
It uses simple rules to decide when to write to memory
The same pattern can be extended to tools, multi-step workflows, or multi-agent systems.
Comparison: Naive Loops vs Mem0-backed Loops
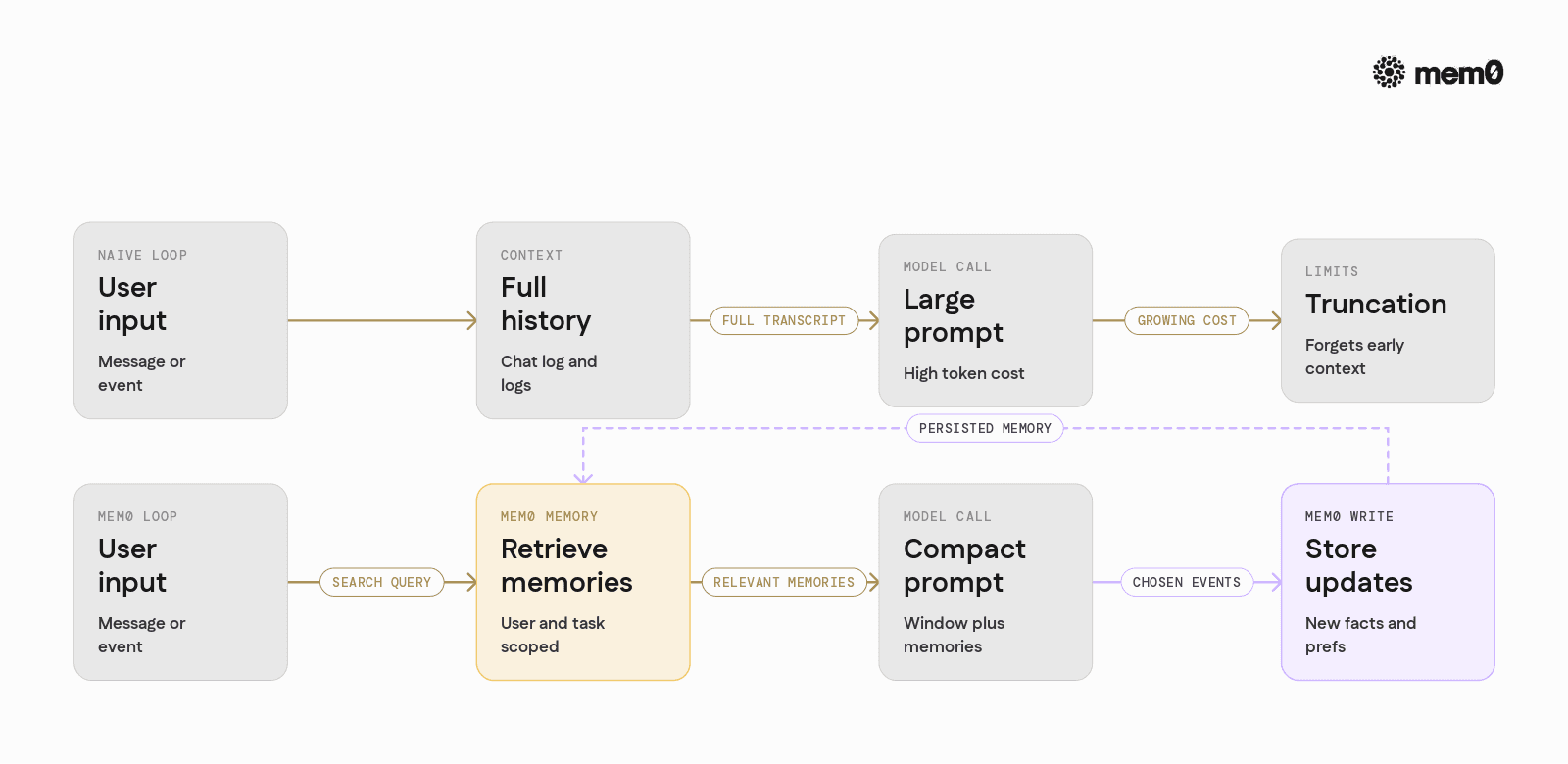
Below is a high-level comparison of a naive token-rich design versus a loop that uses Mem0 for memory.
Aspect | Naive token-rich loop | Mem0-backed loop |
|---|---|---|
Context strategy | Entire chat history in prompt | Small window + retrieved memories |
Token usage per step | High and grows over time | Bounded and controlled |
Long-term memory | Implicit, limited to context window | Explicit, persistent, queryable |
User preference handling | Buried in historical text | Stored as structured memories |
Cross-session behavior | Often resets or uses raw transcript | Stable, user-specific memory over time |
Control of what is remembered | Minimal, mostly truncation at head of context | Flexible policies at read and write |
Maintainability | Hard to modify without breaking prompts | Memory logic isolated from prompt templates |
Scaling to many users | Cost grows quickly with history length | Cost driven by retrieval and targeted memories |
Loop engineering is easier and more reliable when memory is treated as a first-class component instead of a side effect of long prompts.
Use Cases for Loop Engineering with Mem0
Several agent patterns benefit directly from explicit loop engineering and a memory layer.
Personalized assistants
Remember user preferences such as tone, format, tools, and schedule
Store project-specific details and recurring tasks
Maintain context across devices and sessions
Mem0 maintains user-level memories so the loop only needs to fetch what matters for each turn.
Multi-step workflows
Complex tasks like onboarding, troubleshooting, or migration
Agents that must track progress, subgoals, and partial outputs
Flows that pause and resume days later
Mem0 stores workflow state and progress markers, and the loop retrieves the right subset to continue.
Retrieval-augmented agents
Research assistants that read many documents
Code assistants that explore repositories
Agents that maintain summaries over large corpora
Mem0 can store distilled insights, decisions, and key findings. The loop can retrieve both user memories and domain memories in a single interface.
Multi-agent systems
Different agents responsible for planning, execution, oversight
Shared memory for coordination, plus private memory per agent
Logs of disagreements and resolutions
Mem0’s support for different scopes makes it straightforward to design loops where each agent reads and writes to appropriate memory spaces.
Limitations of Loop Engineering Patterns
Loop engineering and memory layers do not eliminate all challenges:
Prompt quality still matters: Even with strong memory, poor system prompts or tool specifications lead to errors. Loop engineering does not replace basic prompt and API design.
Memory policies can be wrong: Deciding what to store and retrieve is non-trivial. Bad policies can clutter memory with noise, which increases retrieval ambiguity and harms responses.
Concept drift and stale memories: Users change preferences, systems change behavior, and tasks evolve. Loops must include strategies to update or discard outdated memories.
Debugging complexity: Multi-step, memory-aware loops can be harder to trace. Engineers need solid logging, replay, and evaluation tooling to reason about failures.
Token-poor loops are not always ideal: Some tasks truly require rich local context, such as editing long documents or multi-file code changes. In those cases, loop engineering is about mixing local context with retrieved memory, not minimizing tokens at all costs.
Mem0 addresses the memory management layer, but loop engineering still requires thoughtful design and evaluation around the model, tools, and product requirements.
Frequently Asked Questions
Q. What is loop engineering in the context of AI agents?
Loop engineering is the design of the control cycle an agent follows to read context, reason, act, and update state over time. It focuses on making that cycle reliable, efficient, and aligned with product goals so agents behave consistently across many steps.
Q. How is loop engineering different from prompt engineering?
Prompt engineering optimizes individual model calls, while loop engineering optimizes how those calls are chained and how state is managed between them. Prompt engineering works at the request level, loop engineering works at the system level across many requests and sessions.
Q. When should an AI team start caring about loop engineering?
Loop engineering becomes important as soon as an agent needs to handle multi-step tasks, persistent user preferences, or cross-session behavior. If prompts are growing uncontrollably and responses become inconsistent over time, it is usually a signal that loop engineering and memory design are needed.
Q. Why is memory so central to loop engineering?
Without explicit memory, the only state an agent sees is what fits in the context window of the current prompt. Memory provides continuity between steps and sessions, allowing agents to remember preferences, progress, and prior decisions, which is essential for realistic, production-grade loops.
Q. How does Mem0 improve token-poor loops?
Mem0 lets agents retrieve a compact set of relevant memories instead of sending entire histories to the model. This keeps prompts small while preserving important context, which reduces cost and latency without sacrificing personalization and task continuity.
Q. Can Mem0 be used with different agent frameworks and models?
Mem0 functions as a standalone memory layer and integrates with any framework or custom loop that can call its API. It is model-agnostic, so teams can change models or agent orchestration code while keeping the same memory behavior.
Further Reading
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or
Self-host mem0 from our open-source GitHub repository.
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

