



MAI-Thinking-1 targets a very specific need for AI engineers. It focuses on chain-of-thought style reasoning, tool use, and multi-step planning without drowning the model in unnecessary chat history. It is built to reason, not just autocomplete.
This post unpacks how MAI-Thinking-1 works, what is new in its design, where it falls short for long-running production agents, and how Mem0 fills the memory gap.
The focus: How to turn MAI-Thinking-1 into a reliable reasoning engine behind production workflows.
What is MAI-Thinking-1
MAI-Thinking-1 is a reasoning-optimized LLM family that separates internal thinking from external responses. It uses structured thought tokens and tool-calling patterns to solve multi-step problems while keeping the visible output clean for end users.
The model is tuned to perform:
Tree and graph-style reasoning over candidate thoughts
Tool and API invocation with intermediate validation
Self-reflection on partial plans, then refinement
Instead of treating prompts as flat text, MAI-Thinking-1 treats a session as a sequence of thought steps, actions, and observations. This makes it suitable for agent-style workloads such as research pipelines, data processing flows, and decision support systems.
What is New in MAI-Thinking-1
MAI-Thinking-1 introduces several shifts compared to more generic chat-optimized models.
Structured internal thinking
The model uses explicit reasoning phases, often marked with special tokens or thought blocks, to perform internal planning. These internal thoughts are not intended for the end user and are often filtered or post-processed by the framework around the model.
This separation lets MAI-Thinking-1 spend more tokens on reasoning while keeping the visible answer compact. In tools-based workflows, the model can think, call tools, inspect results, and revise the plan in multiple loops before finalizing a response.
Tool-centric design
MAI-Thinking-1 treats tools as first-class objects, not just optional helpers. It is trained to:
Decide when a tool is necessary
Select the right tool among many
Format arguments in the schema the tool expects
Interpret tool outputs and continue reasoning
This aligns well with production agents that must read databases, call microservices, or update external systems safely and consistently.
Multi-step problem-solving focus
The instruction tuning for MAI-Thinking-1 emphasizes:
Decomposing tasks into smaller subgoals
Tracking intermediate state across steps
Refusing to shortcut reasoning when context is incomplete
The model is less optimized for casual chat and more aligned with workflows that need dependable logical structure.
Core Architecture and Reasoning Loop
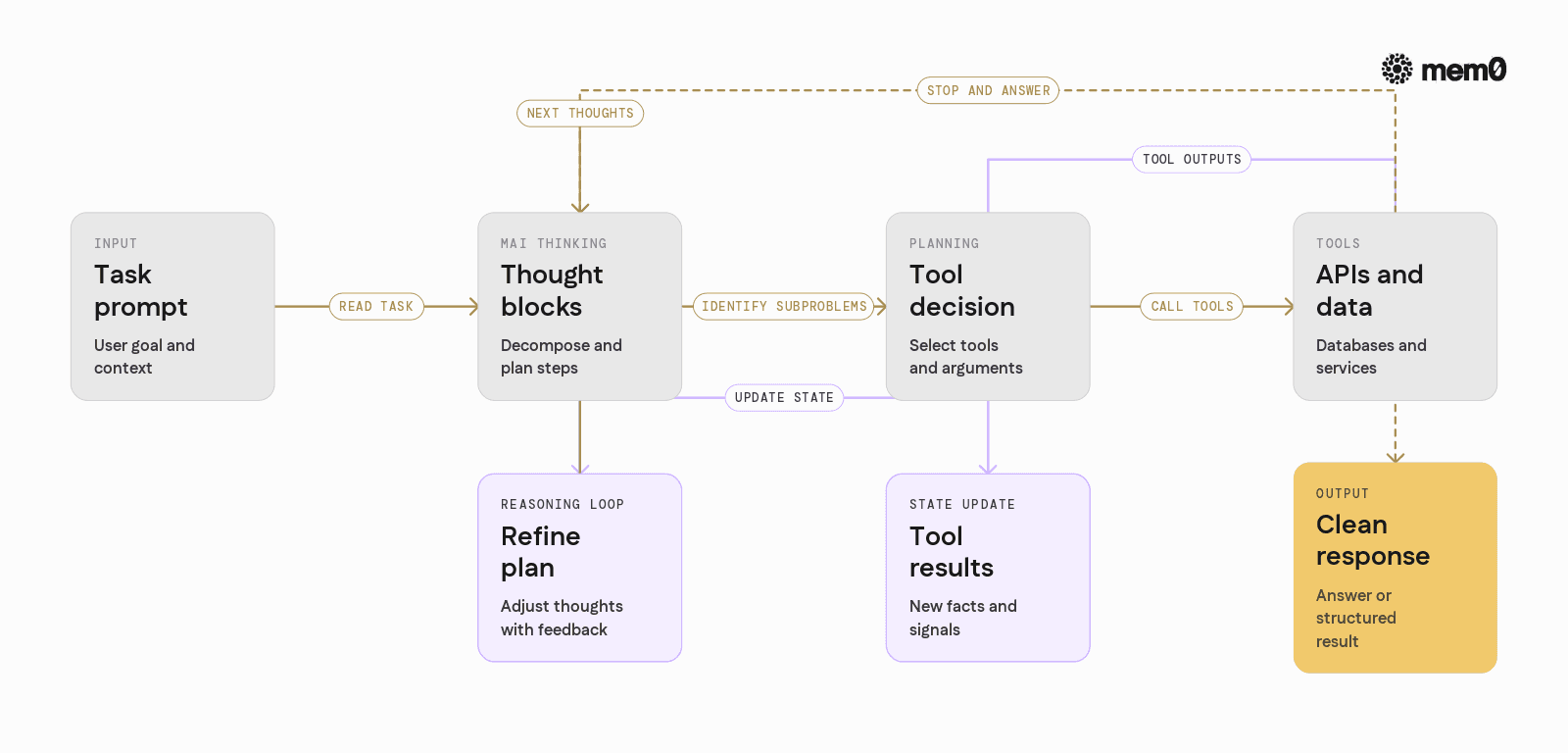
Although implementation details are not all public, MAI-Thinking-1 follows a pattern that is now common in reasoning-focused models but tuned tightly for thinking depth.
A typical MAI-Thinking-1 reasoning loop for a single task looks like:
Read the instruction and existing context.
Generate an internal thought block that identifies subproblems.
Decide whether tools are required and plan their usage.
Call tools, receive outputs, and update an internal state representation.
Iterate on thought blocks and actions until a completion criterion is met.
Emit a clean final answer or structured result.
Frameworks that integrate MAI-Thinking-1 often manage the boundary between internal thoughts and external output. Only the final response is forwarded to the user, while the thought and tool traces are used for debugging, evaluation, and safety checks.
From an engineer’s perspective, MAI-Thinking-1 is less about raw parameter count and more about how its decoding strategies and instruction tuning guide the model to use this loop effectively.
Context, State, and the Memory Problem
MAI-Thinking-1 is strong at reasoning inside a single context window. It can track dozens of steps, revisit earlier decisions, and maintain coherent plans as long as all relevant information fits in the prompt.
Production agents face a different environment:
Sessions span days or weeks.
Users reappear with previous preferences and constraints.
The agent must coordinate across workflows, services, and tasks.
MAI-Thinking-1 itself does not provide persistent memory across requests. It reads whatever is in the prompt, performs its reasoning, and forgets once the response is generated.
This creates three gaps:
Long-term user memory: Preferences, constraints, recurring entities, and historical decisions need to survive across calls.
Cross-workflow state: One MAI-Thinking-1 call may create data that later workflows depend on, such as project plans, research summaries, or approvals.
Context budget constraints: Replaying entire histories inside the prompt causes cost and latency issues and can degrade reasoning clarity.
Persistent, structured memory is needed around MAI-Thinking-1 so it can focus on reasoning in the moment while still behaving as if it remembers the world.
Where MAI-Thinking-1 Excels for Agents
Even with these constraints, MAI-Thinking-1 is attractive for agent builders, especially when integrated into a well-designed system.
Key strengths include:
Planning and decomposition: It can unpack vague human requests into actionable plans with clear steps.
Tool orchestration: It reasons about tool chains, not just single calls, and can adjust based on tool feedback.
Self-correction: When intermediate evidence contradicts earlier assumptions, it can revise its approach within the same context.
Explainable trace: The internal thought and tool traces give engineers a way to inspect how a decision was made, which is useful for debugging and monitoring.
For short-lived workflows where the entire state fits in the window, MAI-Thinking-1 can act as the primary engine. The problem appears when those workflows must be repeated for the same users or evolve.
Where MAI-Thinking-1 Stops
The core limitations relevant to production agents are not about intelligence but about memory and state handling.
No built-in episodic persistence: After the request ends, MAI-Thinking-1 does not remember the conversation or task. New requests must reintroduce all relevant details.
Context window bottleneck: Even with large context, only a fraction of a long history can be included. Selecting the right subset becomes a separate problem.
No native data indexing: MAI-Thinking-1 does not know how to index, search, and rank prior experiences beyond what is fed in context.
Coarse-grained history recall: Serializing entire logs as text and injecting them back into the prompt leads to noisy context. The model sees everything at once and may focus on irrelevant details.
For a single session demo, this is tolerable. For an agent serving thousands of users with complex histories, it becomes a core failure mode.
How Mem0 Fits with MAI-Thinking-1
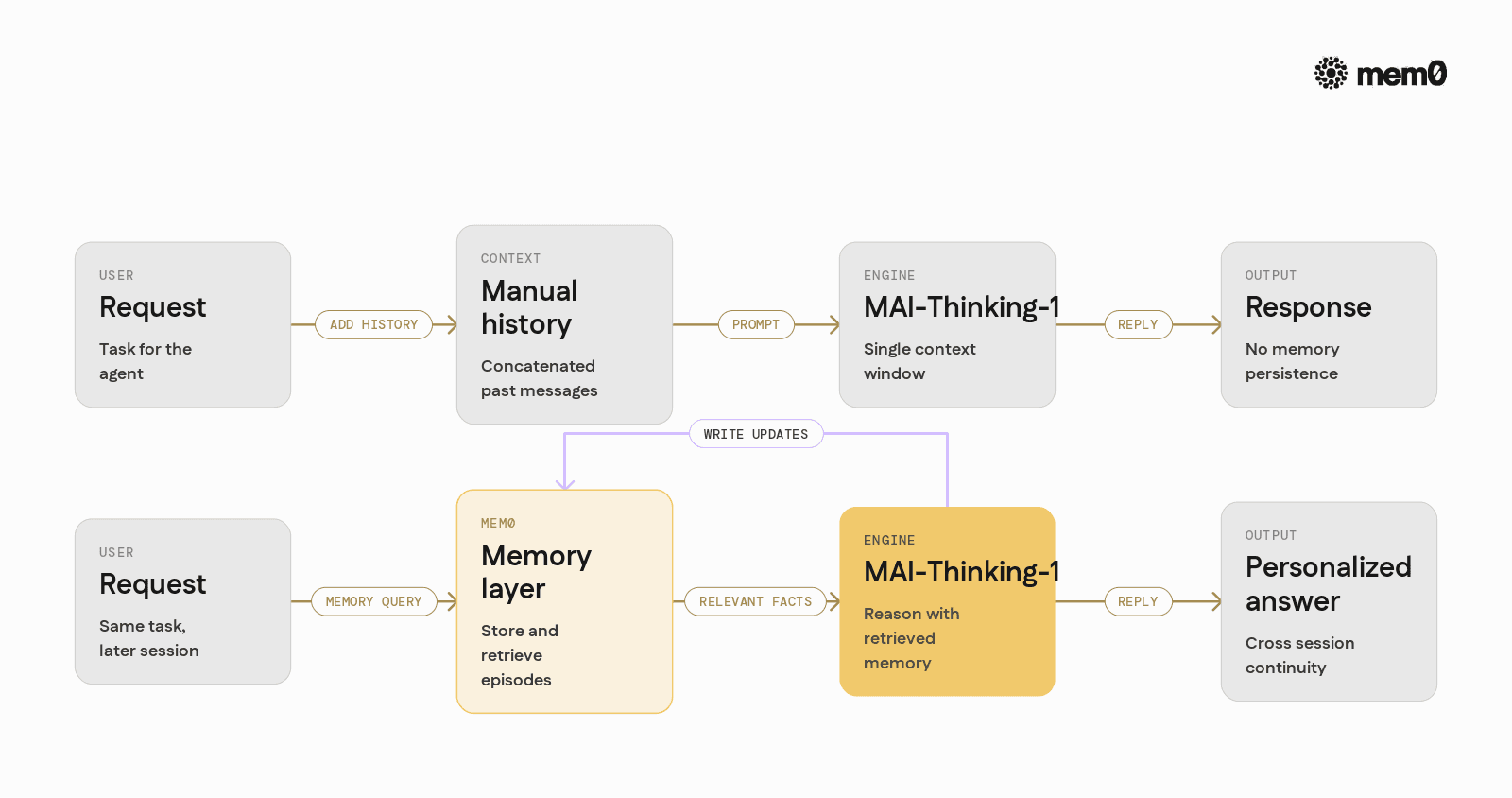
Mem0 sits around MAI-Thinking-1 as an intelligent memory layer that stores, retrieves, and manages agent memories across sessions. It treats memory as a first-class resource, not just concatenated text.
Mem0 provides:
Structured memory objects: Each memory is a typed item with metadata, timestamps, and embeddings.
Automatic extraction: It can infer what should be remembered from model outputs and tool calls.
Retrieval for prompts: It picks the most relevant memories for a new request and formats them as concise context for MAI-Thinking-1.
User-scoped and agent-scoped memory: Memories can be per user, per agent, or global.
With MAI-Thinking-1 focused on reasoning and tools, Mem0 solves the persistent memory dimension and feeds only what is relevant back into the model.
Architectural fit
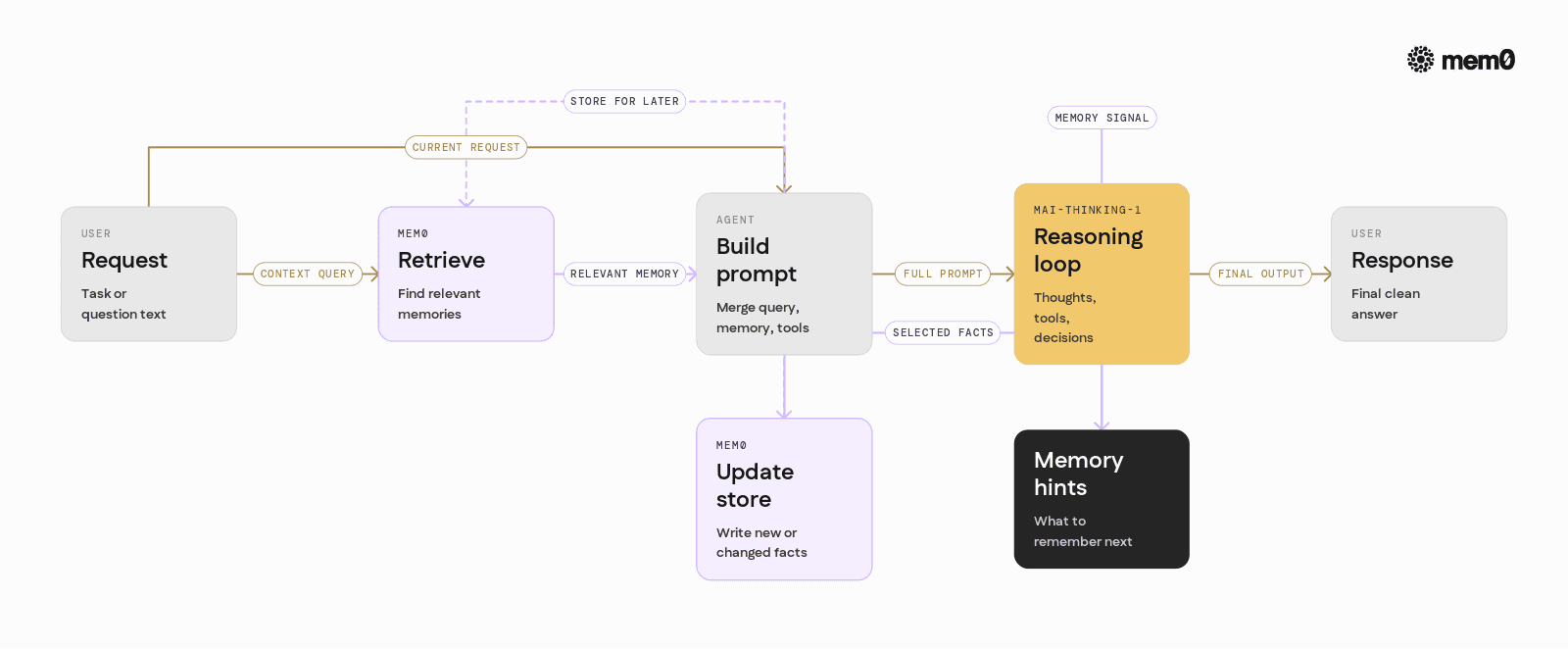
A typical architecture looks like:
User sends a request to the agent.
Agent queries Mem0 for relevant memories using the user ID and query text.
Agent builds a prompt for MAI-Thinking-1, including retrieved memories and tools.
MAI-Thinking-1 reasons, calls tools, and returns a result along with signals about what should be remembered.
Agent sends selected information to Mem0 to update memory.
MAI-Thinking-1 operates in a clean loop. Mem0 maintains continuity across loops.
Example Python Integration with Mem0
The following example shows how an AI engineer might integrate MAI-Thinking-1 with Mem0 in a simple research planning agent. The agent remembers per-user preferences and prior research topics so MAI-Thinking-1 can reason with that context.
Assumptions:
mai_thinking_1_clientis a placeholder for whatever SDK or HTTP client is used to call MAI-Thinking-1.Mem0 is available via the
mem0Python package and configured with an API key.
💡You'll need a free Mem0 API key to run the hosted memory path. Get one at app.mem0.ai: no credit card required.
This pattern keeps MAI-Thinking-1 focused on reasoning. Mem0 owns the job of remembering long-term user preferences and task history, which can be reused across many sessions.
Comparison: MAI-Thinking-1 Alone vs With Mem0
The table below summarizes how MAI-Thinking-1 behaves when used in isolation versus together with Mem0 for production agents.
Capability | MAI-Thinking-1 alone | MAI-Thinking-1 with Mem0 |
|---|---|---|
Long-term user memory | None across requests, per-call only | Persistent per-user episodes with retrieval |
Context management | Manual concatenation of history | Targeted retrieval of relevant memories |
Cross-session personalization | Very limited, requires full history replay | Memory-informed prompts using past preferences |
Scalability with many users | Context window pressure grows quickly | Memory indexing handles growth without bloating prompts |
Debugging and observability | Reasoning trace per call only | Reasoning trace plus structured memory timeline |
Integration effort | Simpler in minimal demos | Slightly higher, pays off for production workloads |
Mem0 does not replace MAI-Thinking-1. It shapes and feeds the right context so the model’s reasoning capabilities are used effectively over time.
Limitations of the Pattern
The MAI-Thinking-1 plus Mem0 pattern is powerful, but not a universal solution.
Quality of memory extraction: If prompts or post-processing heuristics mark the wrong pieces of information as memory-worthy, the memory store can become noisy. This reduces the quality of retrieved context and can confuse the model.
Temporal drift: Some memories expire or change. Without policies for decay, versioning, or conflict resolution, the agent may rely on outdated facts.
Ambiguous identity boundaries: Correct scoping of memory is crucial. If sessions share user IDs incorrectly, Mem0 may cross-contaminate preferences and historical data between users.
Prompt inflation risk: Even with good retrieval, it is possible to include too many memories in each prompt. Engineers must balance recall against prompt size to keep MAI-Thinking-1 focused.
Tool and memory coordination: In workflows where tools also store state, Mem0 and external systems must stay consistent. Otherwise, MAI-Thinking-1 may see memory that conflicts with the actual system state.
These limitations arise from the pattern itself, not from Mem0 specifically. Good design, monitoring, and iteration are required to keep the memory layer aligned with agent behavior.
Frequently Asked Questions
Q. What is MAI-Thinking-1 designed to do best?
MAI-Thinking-1 is designed for multi-step reasoning, tool use, and structured problem solving rather than casual chat. It separates internal thought from final answers so it can plan, call tools, and revise before responding.
Q. How does MAI-Thinking-1 differ from typical chat-oriented LLMs?
Typical chat models focus on conversational fluency and short-turn exchanges. MAI-Thinking-1 is tuned to decompose tasks, perform deeper internal reasoning, and orchestrate tools within a single request.
Q. When should AI engineers add a memory layer like Mem0 around MAI-Thinking-1?
A memory layer becomes important as soon as an agent must remember user preferences or past work across sessions. If the system serves recurring users, performs long-running workflows, or must coordinate decisions over time, Mem0 adds meaningful value.
Q. How does Mem0 decide what to store as memory for MAI-Thinking-1-based agents?
Engineers can combine model instructions, schemas, and heuristics to mark memory-worthy content, such as preferences, commitments, or key facts. Mem0 then stores these as structured items with metadata so they can be retrieved precisely later.
Q. Why not just replay the entire conversation history to MAI-Thinking-1 instead of using Mem0?
Replaying full histories quickly hits context limits, increases token costs, and introduces noise that hurts reasoning quality. Mem0 indexes and retrieves only the most relevant prior information, which keeps prompts compact and focused.
Q. How does Mem0 impact latency and scalability for production agents using MAI-Thinking-1?
Mem0 adds a small retrieval and write overhead, but it reduces the overall prompt size and repeated context tokens. In practice, this often improves scalability because large histories are handled by a database rather than by repeatedly sending them to the model.
Further Reading
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai,
or self-host mem0 from our open-source GitHub repository.
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

