



The core problem these tools try to solve
Hindsight, Supermemory, and Mem0 all target the same bottleneck for production agents: long-term, accurate memory across users and sessions without blowing up context windows or cloud spend.
LLMs are stateless. They forget past interactions as soon as the prompt ends. Naive fixes such as replaying full history or stuffing large chunks into context do not scale. Latency grows, token bills spike, and models start to hallucinate based on partial or redundant context.
A dedicated memory layer addresses three core problems:
What to store
Distilling raw interaction logs into structured, reusable memories.How to organize it
Indexing across users, sessions, tasks, and entities so that agents can retrieve the right facts at the right time.How to retrieve it efficiently
Using semantic, symbolic, and temporal signals so that retrieval stays accurate with millions of items while remaining token efficient.
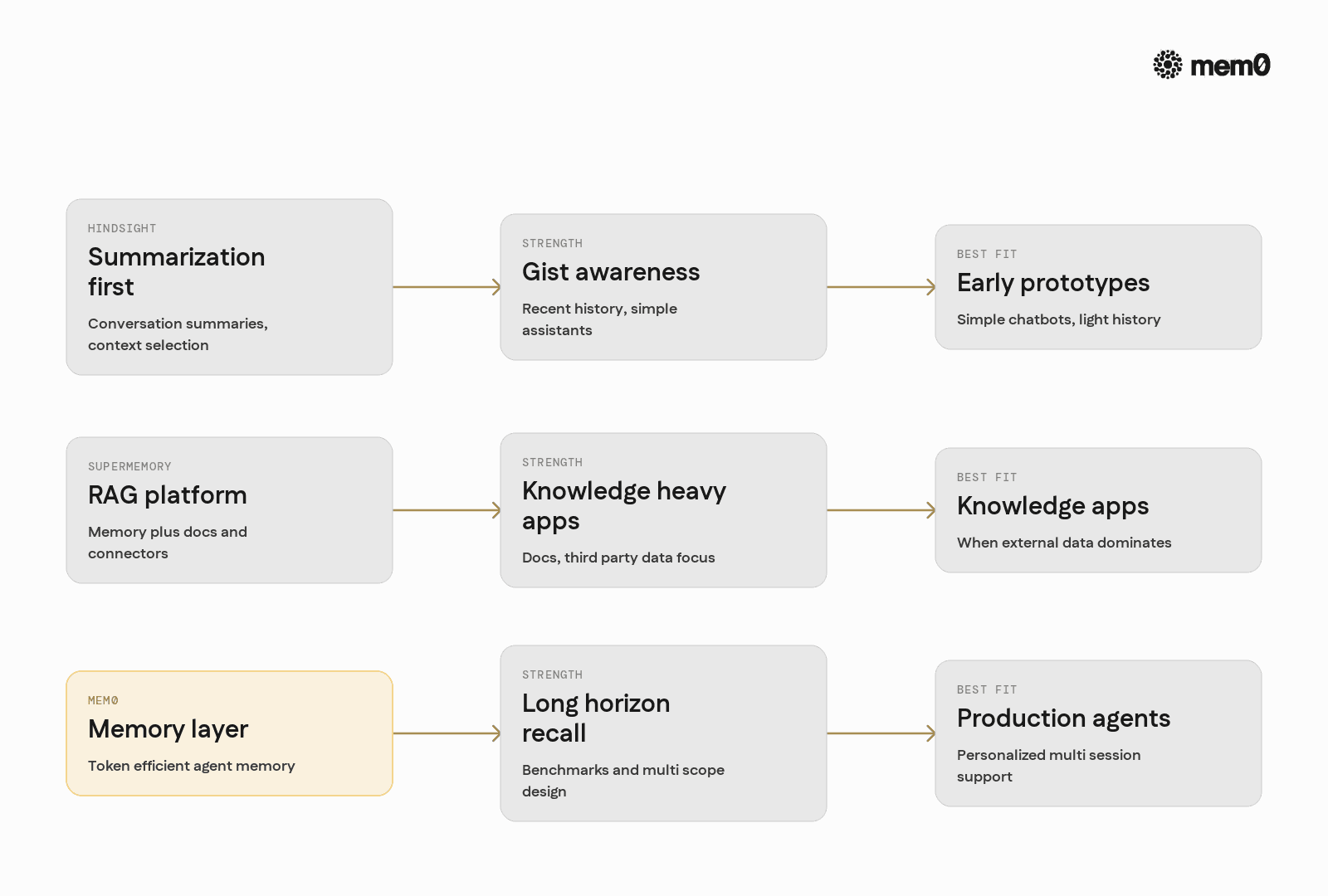
Hindsight, Supermemory, and Mem0 make different tradeoffs in these three areas. Hindsight focuses on retrospective summarization and context selection. Supermemory combines memory with a unified RAG and connector stack. Mem0 focuses narrowly on high-quality, token-efficient, multi-scope memory for production agents.
High level comparison
The table below summarizes how these systems compare at a high level. Values for Hindsight are based on available documentation and typical deployment patterns, not formal benchmarks.
Dimension | Mem0 | Hindsight | Supermemory |
|---|---|---|---|
Primary focus | Long-term agent memory | Conversation summarization and context mgmt | Memory plus RAG, connectors, and user profiles |
Open source | ✅ | Partially (patterns, reference code) | ✅ |
Managed cloud | ✅ | N/A | ✅ |
Long-memory benchmarks | Published (LongMemEval, LoCoMo, BEAM) | Not publicly benchmarked | Partial (LongMemEval) |
Memory scopes | Session, user, agent, org, custom scopes | Mainly conversation / session level | Project / container oriented memory |
Retrieval strategy | Hybrid semantic + keyword + entity | Heuristics and summarization | Vector + metadata + RAG-oriented |
Token efficiency | < 7K tokens per retrieval on evals | Highly variable per summarization strategy | Not disclosed |
Typical use cases | Agents, copilots, CX, coding assistants | Chatbots, assistants with history | Apps that mix memory with external documents |
Self-hosting | ✅ pip / npm / Docker | Yes, as custom infra pattern | ✅ |
Mem0 fits best when the central requirement is reliable, scalable, and token-efficient memory for agents that run continuously, across many users and organizations. Hindsight and Supermemory solve broader or adjacent problems but do not focus as strongly on production, long-horizon memory quality.
How Hindsight-style memory works
Hindsight is a style of memory architecture that many teams implement: log every interaction, then periodically summarize or distill those logs into a compressed representation that can be re-injected into the model prompt.
Common components:
Continuous logging
Store every user and assistant message in a database or vector store.Periodic summarization
Use an LLM to create a summary of the last N interactions, or of the full conversation, and persist that summary as a “hindsight” artifact.Heuristic retrieval
At inference time, choose a mix of:The most recent messages,
One or more long-term summaries,
Possibly a few semantically similar snippets.
Prompt rehydration
Construct a final prompt combining system instructions, user query, recent messages, and summaries.
This pattern is relatively easy to implement and framework agnostic. It works well for:
Simple assistants with limited temporal depth.
Apps that need “gist” awareness more than exact factual recall.
Early prototypes where cost or accuracy at very large scales is less important.
Where it struggles is exactly where production agents need precision:
Summaries often drop rare but important details, such as IDs or preferences.
Repeated summarization can accumulate errors and drift.
Retrieval is tuned by heuristics, not explicit memory objectives or benchmarks.
Scaling to millions of messages per user requires more than summarization.
In short, Hindsight-style systems are great as a starting pattern, but they are not, by themselves, a complete long-term memory layer for production agents.
How Supermemory approaches the problem
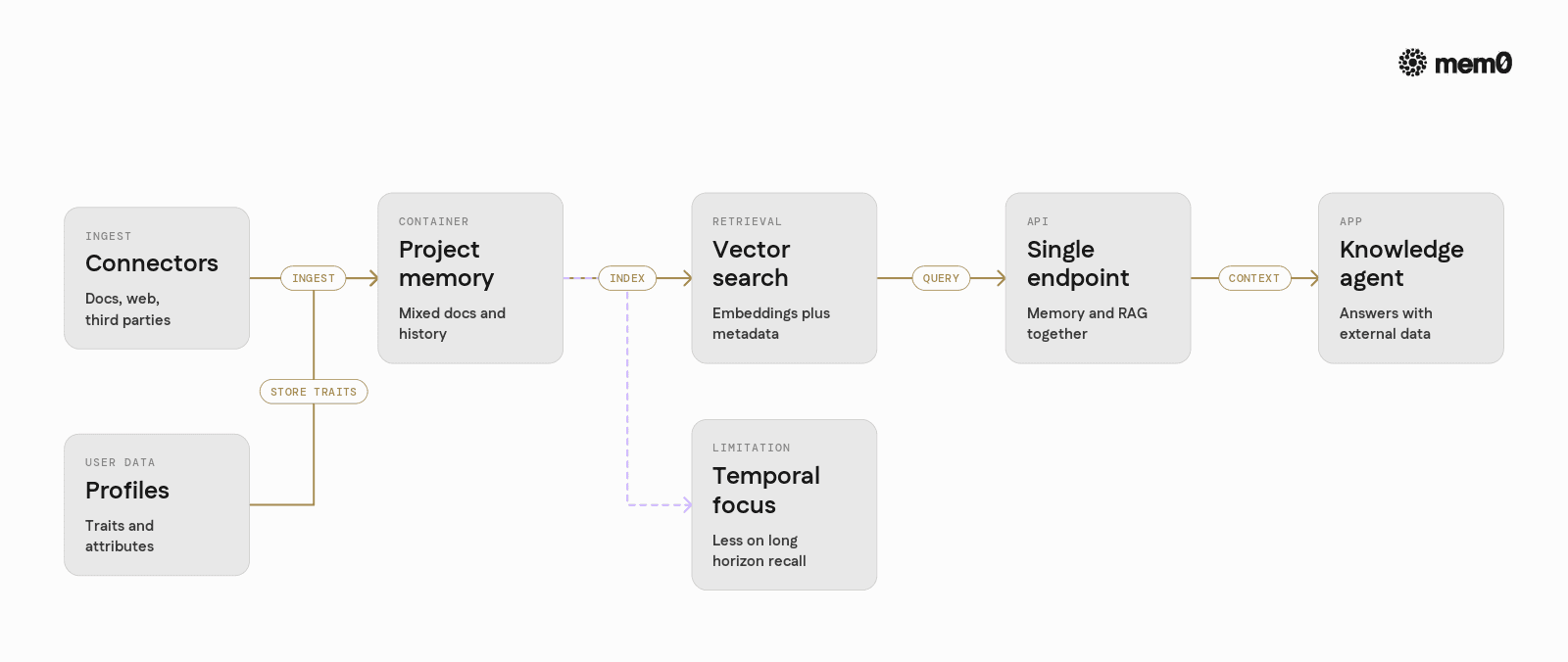
Supermemory targets a broader surface: memory, user profiles, RAG, and external connectors in a single platform.
Typical capabilities include:
Connectors and ingestion
Index documents, web pages, and third-party data sources.Profiles and traits
Store user attributes and traits inferred from interactions.Vector and metadata retrieval
Use embeddings plus metadata filters to pull relevant context.Unified API
One endpoint that handles memory and document retrieval.
This design is attractive for apps that:
Depend heavily on external knowledge bases and documents.
Want to avoid building and operating a separate RAG pipeline.
Prefer an all-in-one platform for data ingestion and retrieval.
However, the broad feature set can lead to tradeoffs for the narrow but hard problem of long-term agent memory:
Long-horizon benchmarks, such as LoCoMo and BEAM-scale tests, are less emphasized or not published.
Architecture is oriented around projects or containers rather than explicit, multi-scope memory addressing (user vs session vs agent vs org).
Retrieval behavior can be tuned for general RAG relevance instead of strict memory fidelity across hundreds of sessions.
Supermemory is well suited for knowledge-heavy apps where memory is one part of the stack. For agents whose main value is personalized, long-term interaction, a more focused memory layer is often required.
How Mem0 solves the core memory problem
Mem0 is designed specifically as a memory layer for LLMs and agents. It focuses on three goals:
Accurate long-term memory across sessions
Published results include:LongMemEval: 94.4
LoCoMo: 92.5
BEAM 1M / 10M: 64.1 / 48.6
Token-efficient retrieval
Mem0 averages under 7K tokens per retrieval on LongMemEval-S, compared to about 115K tokens for full-context approaches. This is a 16x reduction, with higher or comparable accuracy.Multi-scope memory architecture
Mem0 explicitly models:Session-level memory
User-level memory
Agent-level memory
Organization-level memory Plus custom collections and scopes when needed.
Internally, Mem0 uses:
Single-pass extraction
It extracts memories from raw interactions in one pass, which avoids repetitive summarization and compounding errors.ADD-only history for factual continuity
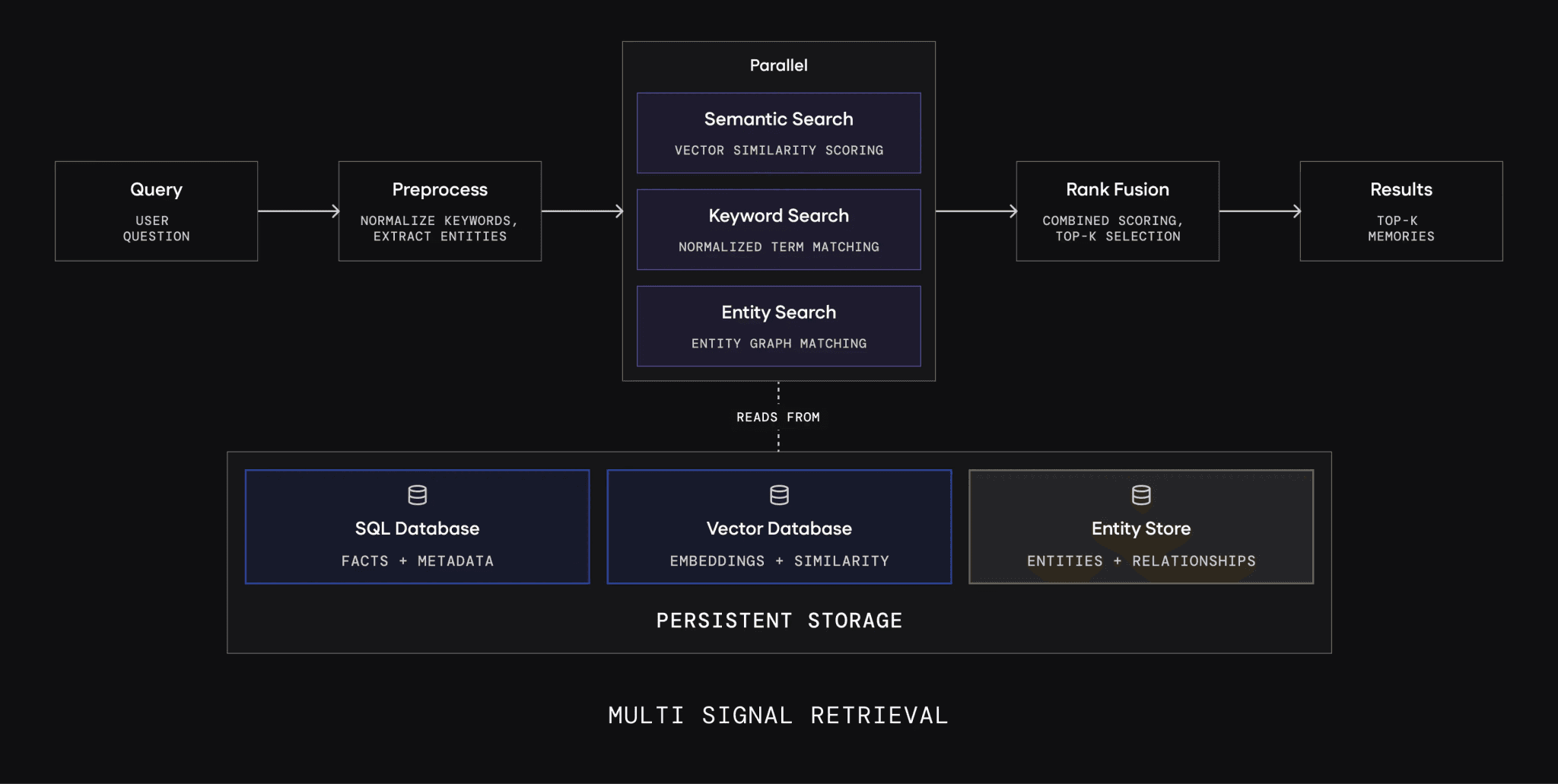
Instead of rewriting or mutating existing memories, Mem0 tends to add new entries that are linked via entities and metadata. This keeps a traceable history that the model can reason about.Hybrid retrieval strategy
Retrieval combines:Semantic similarity,
Keyword and symbol matching,
Entity and graph-like relationships.
The result is more stable recall, especially for long-tail facts or rarely mentioned details.
These choices address the core weaknesses of Hindsight and generic RAG-style memory when used as the sole memory mechanism for agents.
Mem0 vs Hindsight vs Supermemory in production
For AI engineers building production agents, there are a few recurring design questions:
Should memory be summarization-centric or fact-centric?
Where should external knowledge retrieval live relative to user and agent memory?
How can memory be tested and benchmarked like any other critical component?
The table below focuses on production-oriented dimensions.
Aspect | Mem0 | Hindsight pattern | Supermemory |
|---|---|---|---|
Memory representation | Structured memories with metadata | Summaries plus raw logs | Vector segments plus profiles and metadata |
Long-term factual recall | High, benchmarked | Medium, depends on prompt and heuristics | Good for RAG facts, less focused on temporal evals |
Cost at scale | Bounded, token-efficient retrieval | Grows with history and summarization | Tied to RAG usage and context sizes |
Multi-tenant support | Built-in scopes (user, org, agent) | DIY in database schema | Project / container segmentation |
Testing and evaluation | Benchmarks and harness integrations | Custom, ad hoc | Partial, mostly relevance-oriented |
Ideal use case | Persistent, personalized agents | Simple assistants, early prototypes | Knowledge apps with heavy external data |
A common pattern in production stacks is:
Use a dedicated RAG pipeline or data platform for external knowledge.
Use Mem0 as the memory layer for user, agent, and org context.
Use summarization only as a secondary tool (e.g. generating human-readable recaps), not as the anchor for memory.
Integrating Mem0 into an agent in Python
The following example shows a minimal, working integration of Mem0 into a Python agent loop. It assumes use of the mem0ai Python package and any compatible chat model.
Install the library first:
Set the required environment variables:
Then integrate Mem0 in a conversational loop:
This shows a few core properties:
Mem0 automatically handles extraction and indexing. The agent simply sends raw messages.
Retrieval is scoped by
user_idandagent_id, which makes it safe for multi-tenant or multi-agent systems.The token cost of
memory_contextis controlled by Mem0’s retrieval algorithm instead of naive “append everything” history.
To add organization-level or team-level memory, the calls can include org_id as well, and retrieval can merge scopes according to business rules.
Example use cases where Mem0 is preferable
Several production scenarios highlight why a dedicated memory layer such as Mem0 is important.
Multi-session customer support assistants
A single user might interact with a support agent dozens of times over weeks. The agent needs to remember:
Past issues and resolutions,
Products owned, usage patterns, and preferences,
Escalation history and special conditions.
Summarization alone tends to omit critical identifiers or edge-case rules. A unified RAG system often mixes product documentation with user history in ways that are difficult to audit. Mem0 keeps user-level and org-level memories separate and queryable, which makes it easier to reason about and test what the agent “knows” about each customer.
Developer copilots with persistent project context
For coding assistants embedded in IDEs, the memory problem looks different:
The assistant must remember user preferences, common libraries, and coding style.
It may need to track long-running refactors or TODOs that span many sessions.
External knowledge (docs, repos) can be handled with separate RAG pipelines.
Mem0 can store long-term project intentions and developer-specific facts as structured memories, while the IDE or backend handles file-level embeddings. Hindsight-style summarization of coding sessions is helpful for logs, but not sufficient for precise recall of key decisions or constraints.
Multi-agent workflows and orchestration
When several agents collaborate on a workflow, each agent might have:
Its own internal memory (tools used, decisions made),
Access to shared org-level memory (policies, constraints),
Access to user-level memory (preferences, past outcomes).
Mem0’s explicit scopes (user, agent, org) provide a clean interface for orchestration frameworks. An orchestrator can route memory read/write operations to the correct scope for each agent, instead of mixing all state into a single project container or summary.
Limitations of these memory patterns
Each pattern has limits that engineers should factor into architecture decisions.
Hindsight-style systems
Summaries are lossy and can drift over time, which reduces factual precision.
Heuristic retrieval is often brittle, especially as history grows large.
There is no standard way to benchmark performance beyond ad hoc tests.
Hindsight is a productive pattern for early-stage systems, but teams often outgrow it as they scale user counts and conversation depth.
Supermemory-style, RAG-centric systems
The focus on connectors and document ingestion can overshadow fine-grained control of agent memory.
Temporal reasoning and multi-session recall are harder to test when memory and knowledge are blended into the same retrieval channel.
When external data is not central to the product, the platform can feel heavier than needed.
Supermemory-like systems are powerful for knowledge-heavy apps but can be overkill, or under-specialized, for agents where user and session memory is the main problem.
Dedicated memory layer with Mem0
While Mem0 addresses many gaps, a dedicated memory layer also requires:
Intentional integration
Agents must explicitly write and read from Mem0, which means updating agent loops and orchestration logic.Clear boundaries with RAG
External knowledge and persistent memory should be separated conceptually and in code, which adds some design work.Monitoring and evaluation
Teams need to adopt benchmarks (such as LongMemEval-style tests) or their own harnesses to track memory quality over time.
These are tradeoffs that come with treating memory as a first-class component. For production agents, this is usually the right level of rigor.
Frequently Asked Questions
When should an engineering team choose Mem0 over Hindsight-style summarization?
Mem0 is preferable once agents need accurate recall over many sessions or across millions of events. Hindsight summarization is useful early on, but it rarely scales cleanly in terms of accuracy, cost, or maintainability. When memory quality affects product outcomes or SLAs, Mem0’s dedicated architecture and benchmarks offer a more reliable foundation.
How does Mem0 differ from a generic vector store used as memory?
A generic vector store provides embeddings and similarity search, but it does not solve extraction, multi-scope modeling, or token-efficient retrieval by itself. Mem0 includes extraction logic, entity linking, hybrid retrieval, and opinionated APIs for user, session, agent, and org scopes. This reduces the amount of custom glue code and heuristic logic that teams need to build and maintain.
Can Mem0 and Supermemory be used together in a stack?
Yes, they can coexist. A common pattern is to use Supermemory or a similar system for document ingestion and external knowledge, while delegating user, agent, and org memory exclusively to Mem0. This separation keeps personalized memory predictable and testable, while still benefiting from rich RAG capabilities for documents and third-party data.
How does Mem0 maintain token efficiency compared to full-history approaches?
Mem0 extracts memories in a single pass and retrieves a focused subset based on semantic, keyword, and entity signals. This avoids replaying entire histories or large contextual windows, which can reach hundreds of thousands of tokens. Benchmarks show under 7K tokens per retrieval on LongMemEval-S, compared to roughly 115K tokens for full-context methods, while achieving higher accuracy.
What is required to self-host Mem0 in a production environment?
Self-hosting Mem0 typically involves deploying the open-source package with Docker, configuring a backing database, and configuring API keys. The deployment can run inside a VPC alongside application services to satisfy compliance requirements. The same APIs used in the managed cloud work in self-hosted mode, so application code does not need to change.
How should teams test memory quality when adopting Mem0?
Teams can adopt published benchmarks such as LongMemEval and LoCoMo as inspiration, then design their own task-specific evaluation suites. A practical approach is to synthesize long-horizon user journeys, log interactions through the agent, and periodically query Mem0 for critical facts that should be remembered. Comparing ground truth labels with Mem0’s retrieved memories provides a measurable signal for regression tests and model updates.
Further Reading
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

