



Modern teams expect code review automation to be consistent, context-aware, and incremental. A static LLM prompt that comments on a single diff cannot meet those expectations. It ignores historical decisions, prior review feedback, and project-specific conventions.
A code review agent that operates in production needs a memory layer. It must remember comments across pull requests, recognize recurring patterns in a repository, and adapt to individual contributors. This article explains how to build such an agent, and how Mem0 solves the memory problem in that workflow.
The focus is practical. By the end, readers will have a working Python example that connects Mem0 to a code review loop and can be expanded into a production system.
👉Get a free API key at app.mem0.ai to follow along (free tier, no credit card, includes all the
add()andsearch()calls shown below).
The Problem Space for Code Review Agents
Code review agents usually start simple. They receive a diff, call an LLM with a generic prompt, and output comments. This works for toy examples and fails in live repositories.
Key gaps emerge:
The agent does not know the repository’s history or prior decisions
The agent repeats the same comments to the same developer
The agent cannot track long-running refactors or epics
The agent cannot adapt to evolving style guides or architecture
Most of these issues are not about the model. They are about memory. Without a persistent state across sessions, every review is treated as a clean slate, which is the opposite of how human reviewers operate.
Persistent memory lets the agent:
Accumulate repository knowledge over time
Encode explicit decisions, such as "we accept this pattern here"
Track developer-specific feedback and learning progress
Improve its suggestions as it sees more code
This is the core role Mem0 plays.
What Mem0 Is in the Context of Code Review
Mem0 is an open-source memory layer for LLMs and agents. In practice, for a code review agent, it acts as three things:
A long-term memory store across pull requests
A context retrieval mechanism for each new review
A structured way to tag and query memories by project, file, and developer
Instead of storing arbitrary JSON blobs, Mem0 stores semantically indexed memories of:
Review comments
Final decisions or resolutions
Repository-specific rules and heuristics
Metadata about files, services, and modules
Each memory can be attached to:
A repository ID
A file path or module path
A developer or team identity
The nature of the issue (security, style, performance)
Mem0 sits between the code review integration layer (for example, a Git hosting platform webhook) and the LLM engine. It gives the agent historical context and gives engineers a clear interface to inspect and manage what the agent remembers.
Architecture of a Mem0-Powered Code Review Agent
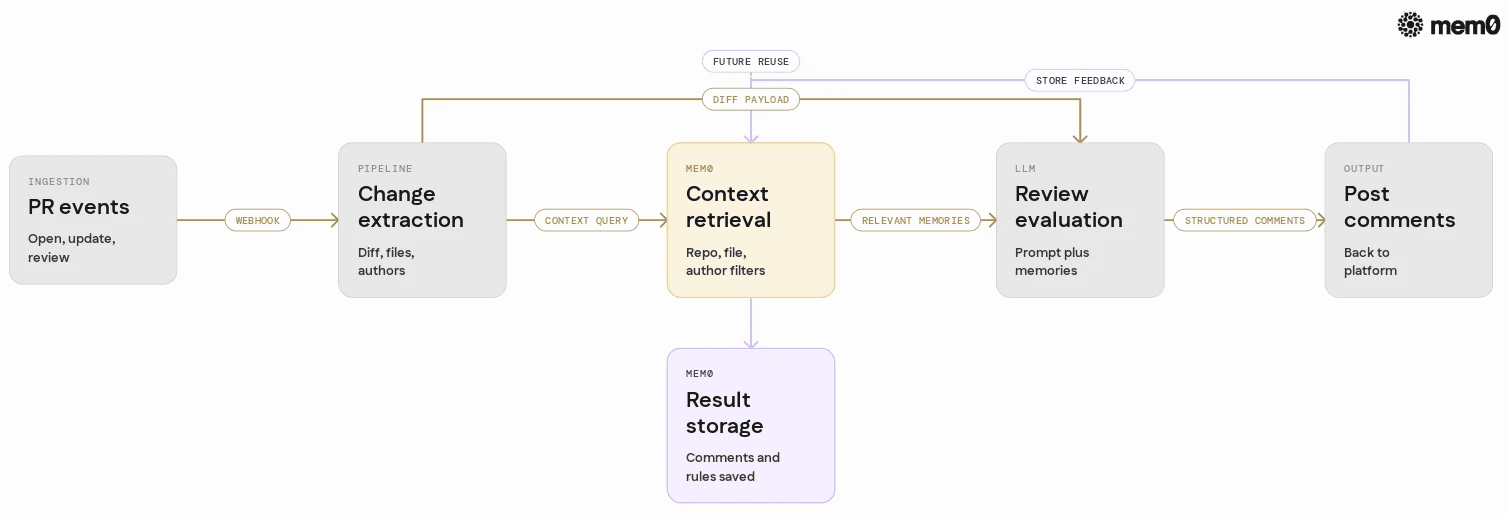
A production code review agent has several moving parts. The memory layer must fit into a pipeline that looks roughly like this:
Event ingestion
Pull request opened or updated
Commit pushed to a branch
Review requested
Change extraction
Compute diffs
Extract file paths and metadata
Identify authors and reviewers
Context assembly
Query Mem0 for relevant memories
Gather repo-level rules and prior feedback
Aggregate examples of similar issues
LLM evaluation
Build a prompt containing diff and retrieved context
Call the LLM for suggestions and comments
Parse structured responses
Result persistence
Post comments back to the code hosting platform
Write new memories to Mem0
Tag those memories for future retrieval
Iteration
On future pull requests, retrieve and reuse prior decisions
Adapt over time as new patterns emerge
Mem0 primarily affects steps 3 and 5. It must be cheap and straightforward to:
Store new review events as memories
Query by repository, file, and developer
Filter and rank memories for the current diff
Keep the retrieved context within token limits
The remaining sections walk through how to implement these pieces with real Python code.
Setting Up Mem0 in a Python Code Review Agent
This example uses Python, an OpenAI model, and Mem0 as the memory layer. Installation can be done via pip:
The example assumes environment variables for:
MEM0_API_KEYOPENAI_API_KEY
A minimal Mem0 client setup:
👉Wanna give it a try? Get a Mem0 API Key and try it yourself.
Next, define a small configuration object to capture repository and developer identities. This simplifies memory tagging and retrieval.
In a production integration, repo_id, pr_id, and author_id would be derived from webhook payloads from the code hosting provider.
Storing Review Memories with Contextual Metadata
The power of Mem0 for code review agents comes from structured memory. Each memory entry should contain:
Natural language content summarizing what happened
A set of metadata fields, such as
repo_id,file_path,issue_type, andauthor_id
Suppose the agent generates a comment on a diff. After posting it to the code hosting platform, store it in Mem0:
Certain patterns benefit from storing higher level decisions as separate memories. For example, when a team agrees on a custom rule, store that as a reusable memory.
Over time, these entries form a knowledge base of the repository and its norms. Each new review can be retrieved from this base.
Retrieving Relevant Context for Each Review
Retrieval is where Mem0 directly improves the quality of code review comments. For each file or diff chunk, query for the most relevant historical memories.
Key filters and query patterns:
Limit by
repo_idfor repository-specific contextFilter by
file_pathor prefix for module-specific patternsFilter by
author_idto recall personal feedbackFilter by
issue_typewhen focusing on a specific class of issue
A sample retrieval function:
For a broader context, for example, repository-level rules, call search with only repo_id filter and a different query text. Combine both sets of memories when building the LLM prompt.
The agent now has both file-specific and repository-wide context for each review.
Generating Context-Aware Code Review Comments
With retrieval in place, the next step is constructing prompts that integrate Mem0 context with the current diff. The pattern below uses the OpenAI Python SDK with a structured system and user prompt.
Then the call to the LLM:
Each comment from run_review can then be posted to the code hosting platform and stored in Mem0 via store_review_comment. This closes the loop and ensures that future reviews inherit current decisions.
Aligning Mem0 Memory with Code Review Workflows
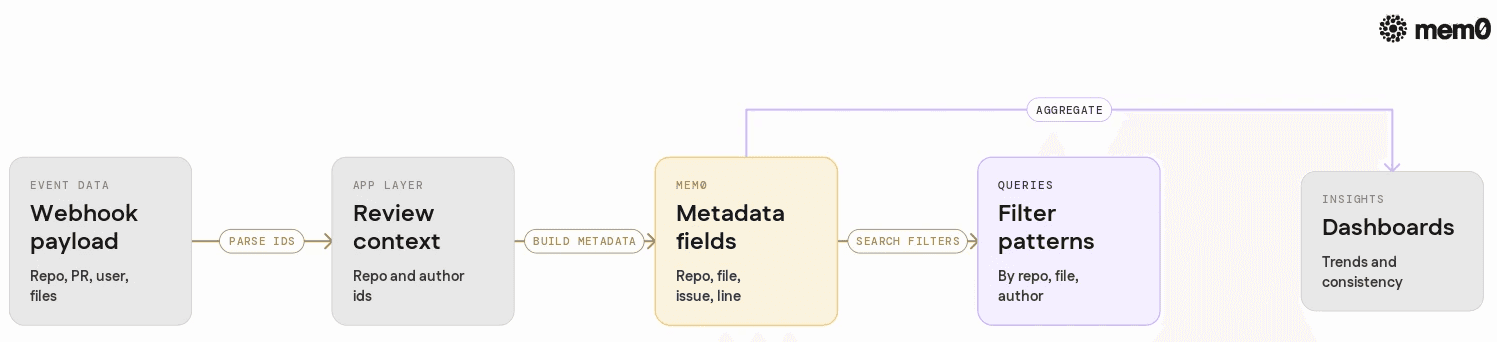
Mem0 must align with real workflows, not theoretical ones. In practice, that means mapping Mem0 metadata to key concepts in the code review lifecycle:
repo_idmaps to the repository or project slugpr_idmaps to the pull request or merge request IDcommit_idcan be stored when needed for debuggingauthor_idandreviewer_idmap to users in the code hosting platformfile_pathand optionalmodulefields map to paths in the repository
Example metadata design:
This design enables:
Filtering out memories that belong to other repositories
Clustering feedback by file or module
Analyzing per-author trends, for example, recurring security issues
Building dashboards or metrics on top of Mem0 content
The same structure allows the agent to adapt to different code hosting providers. The Mem0 layer remains unchanged while the ingestion and posting layers are swapped out.
Comparison of Stateless vs Mem0-Based Code Review Agents
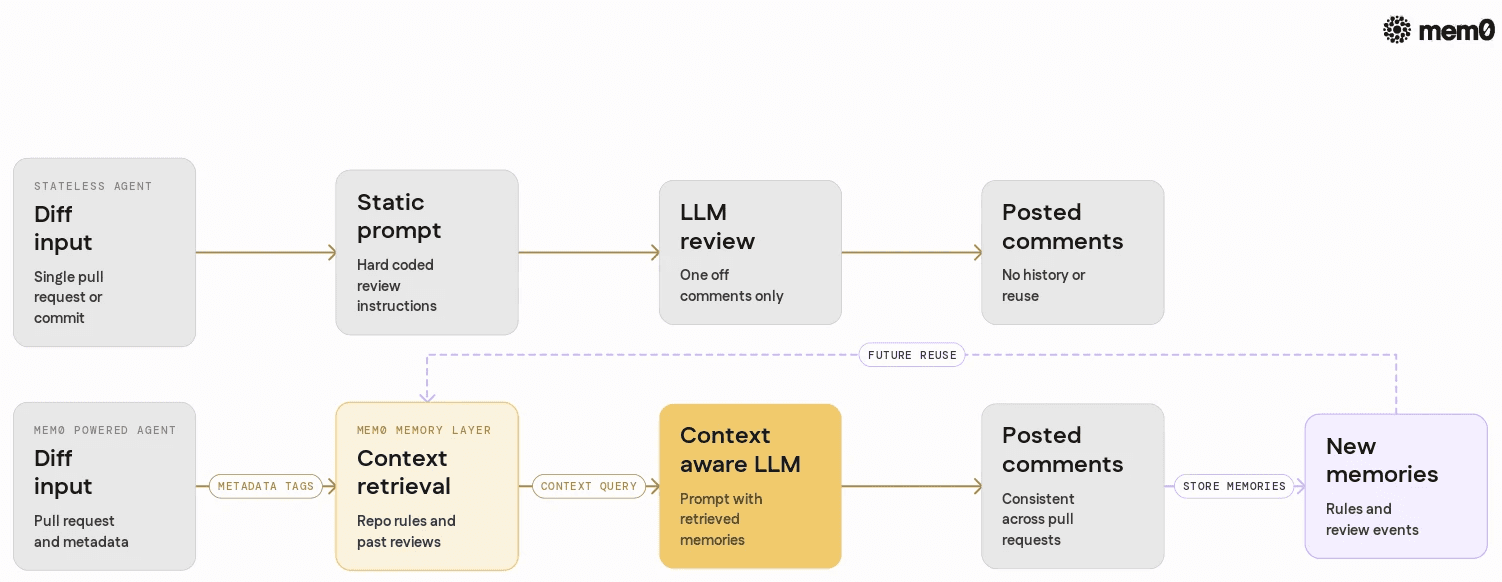
The main difference between a naive code review agent and one using Mem0 is not the model. It is the persistence and reuse of knowledge.
Aspect | Stateless LLM Review Agent | Mem0-Powered Review Agent |
|---|---|---|
Awareness of past decisions | None, every review is fresh | Remembers previous comments, resolutions, and rules |
Repository-specific rules | Hard-coded or prompt-only, easy to drift out of sync | Stored as memories, updated organically via reviews |
Consistency across PRs | Inconsistent, depends on prompt phrasing and model state | High, the model is guided by retrieved historical context |
Developer personalization | Not possible | Per-author memories enable tailored feedback |
Handling of long-running work | Does not track refactors or epics | Can recall prior phases and align with earlier guidance |
Token usage | All context baked into one prompt | Compact prompt plus retrieved, relevant memories |
Operational observability | Difficult to reason about model behavior | Mem0 content acts as an audit log of agent reasoning |
Evolution over time | Static unless prompts are manually updated | Learns from the accumulated repository history |
For production AI engineers, the key benefit is predictability. The Mem0 layer turns the code review agent into a system that converges to stable behavior rather than producing one-off responses.
Limitations of Code Review Agents with Persistent Memory
Adding Mem0 solves the memory gap, but it does not make a code review agent omniscient. Certain limitations remain important.
First, the agent can only reason about what it sees. If the diff omits context or tests, the model might miss issues. Mem0 can store prior context, but it still operates within token budgets and the quality of retrieved memories.
Second, memory selection matters. Poor filters or overly broad queries can flood the prompt with irrelevant history. This can distract the model or increase latency. Engineers must tune filters to balance recall and precision.
Third, performance and latency are non-trivial. Large repositories and high review volume can create significant memory traffic. Caching and batching retrieval or storing higher level summaries can mitigate this, but the design must treat Mem0 as a critical dependency.
Fourth, human oversight remains necessary. The agent can provide consistent, context-aware feedback, but it can also propagate bad rules or decisions if those were stored in memory. Processes should exist to edit or remove incorrect memories and to align the system with updated policies.
Finally, domain-specific correctness is still challenging. Highly specialized codebases, such as numerical libraries or hardware interfaces, might require domain knowledge beyond what the model and memory can provide. In such cases, Mem0 can assist but not replace expert human review.
Frequently Asked Questions
Q. What is the main benefit of adding Mem0 to a code review agent?
Mem0 provides persistent, queryable memory across pull requests and sessions. This lets the agent remember past comments, repository-specific rules, and developer patterns, which yields more consistent and context-aware reviews over time.
Q. How does Mem0 differ from just using a database for logs?
A traditional database stores structured records but does not provide semantic search for natural-language content. Mem0 stores memories with embeddings and metadata, so the agent can retrieve relevant past context based on meaning, not just exact matches or IDs.
Q. When should a team introduce Mem0 into a code review workflow?
Mem0 becomes valuable once the repository and team reach a scale where consistency and history matter. This typically happens when multiple reviewers are involved, custom standards evolve over months, or recurring issues appear that the agent should recognize and remember.
Q. How does Mem0 handle multi-repository setups or microservices?
Each repository can be assigned a distinct repo_id so memories remain scoped properly. Teams can also tag services or modules in metadata, which allows the agent to reuse patterns across related repositories while still separating unrelated projects.
Q. What models work with Mem0 in this code review pattern?
Mem0 is model-agnostic. Any LLM that can accept text prompts and return text responses can be integrated, whether via OpenAI, local models, or enterprise providers, as long as the agent code passes Mem0’s retrieved context into the prompt.
Q. Why store both review comments and rules in Mem0 instead of only rules?
Rules capture explicit decisions, but review comments reflect real-world application of those rules and exceptions. Storing both gives the agent a richer set of examples to reference, which helps it understand nuance and avoid overly rigid or repetitive feedback.
Further Reading
—
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or
Self-host mem0 from our open source GitHub repository.
—
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

