



Introduction
Production agents live on memory quality. Routing, tools, and prompts all help, but without reliable recall across long horizons, agents forget user specifics, repeat questions, and hallucinate context. Platforms like Honcho package long-term memory into a managed service, while Mem0 focuses on a dedicated, open memory layer that fits into any agent stack.
This post compares Mem0 and Honcho from the perspective of AI engineers shipping production agents. It focuses on the core memory problem, how each platform approaches it, where those approaches stop, and how Mem0’s token-efficient algorithm and memory model change the tradeoffs.
What Mem0 and Honcho Are
Honcho provides a managed memory service for AI agents. It focuses on storing conversations, extracting salient facts, and retrieving them for later use. Its goal is to abstract away the complexity of embedding stores, retrieval logic, and persistence so agents can add “remembering” with minimal code.
Mem0 is an open-source memory layer built for LLMs and agents. It focuses on:
Long-term, cross-session memory
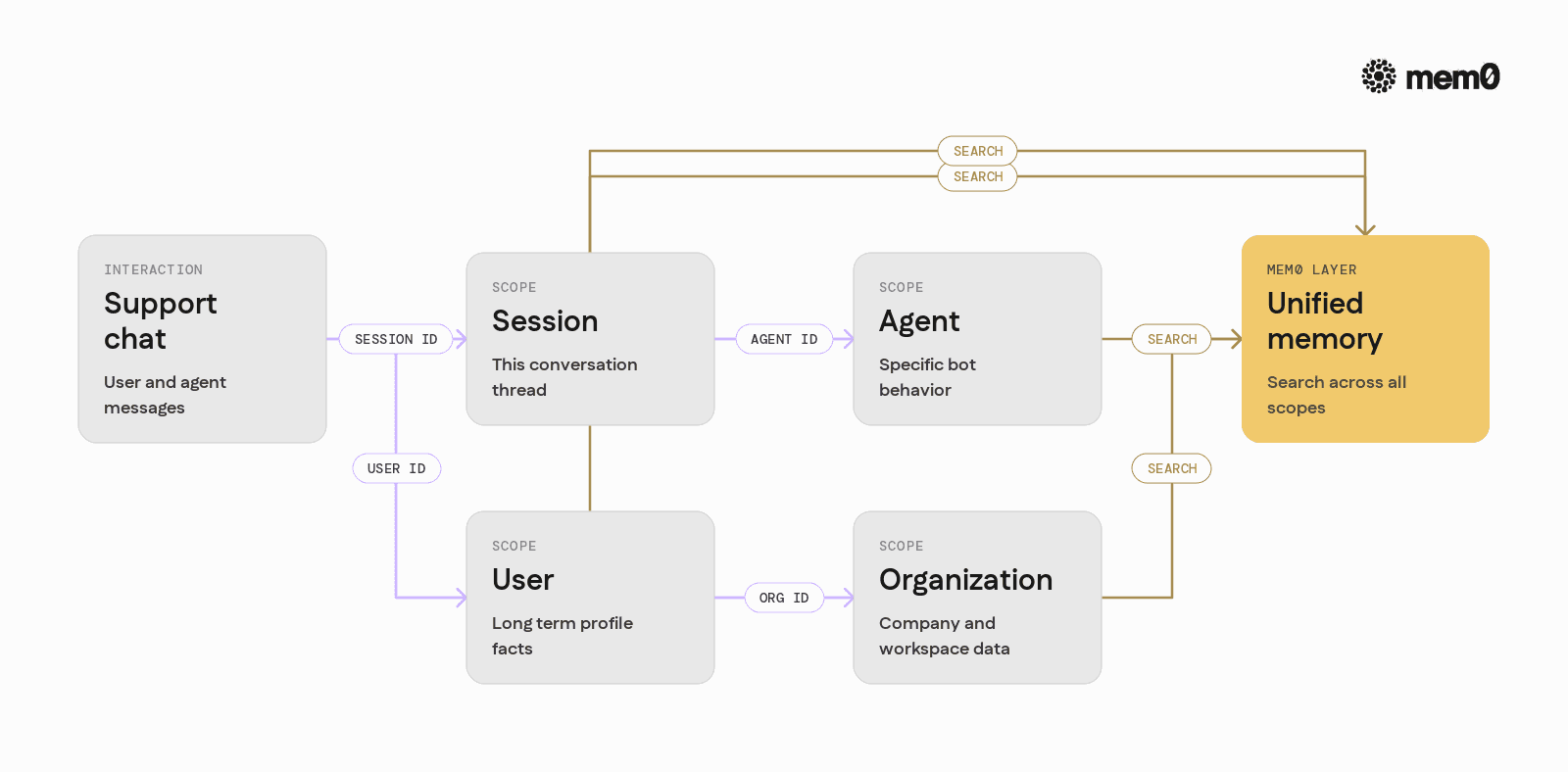
Multi-scope memory across users, sessions, agents, and organizations
Token-efficient retrieval that avoids full-history injection
Clean abstractions that plug into existing frameworks like LangChain, LlamaIndex, and custom agent stacks
Both target the same core need, but with different design priorities. Honcho is a managed memory service. Mem0 is an open memory substrate that can run as a managed API or as self-hosted infrastructure.
High-Level Comparison
For engineers choosing between the two for production agents, the differences center on openness, scopes, and retrieval behavior.
Mem0 vs Honcho at a Glance
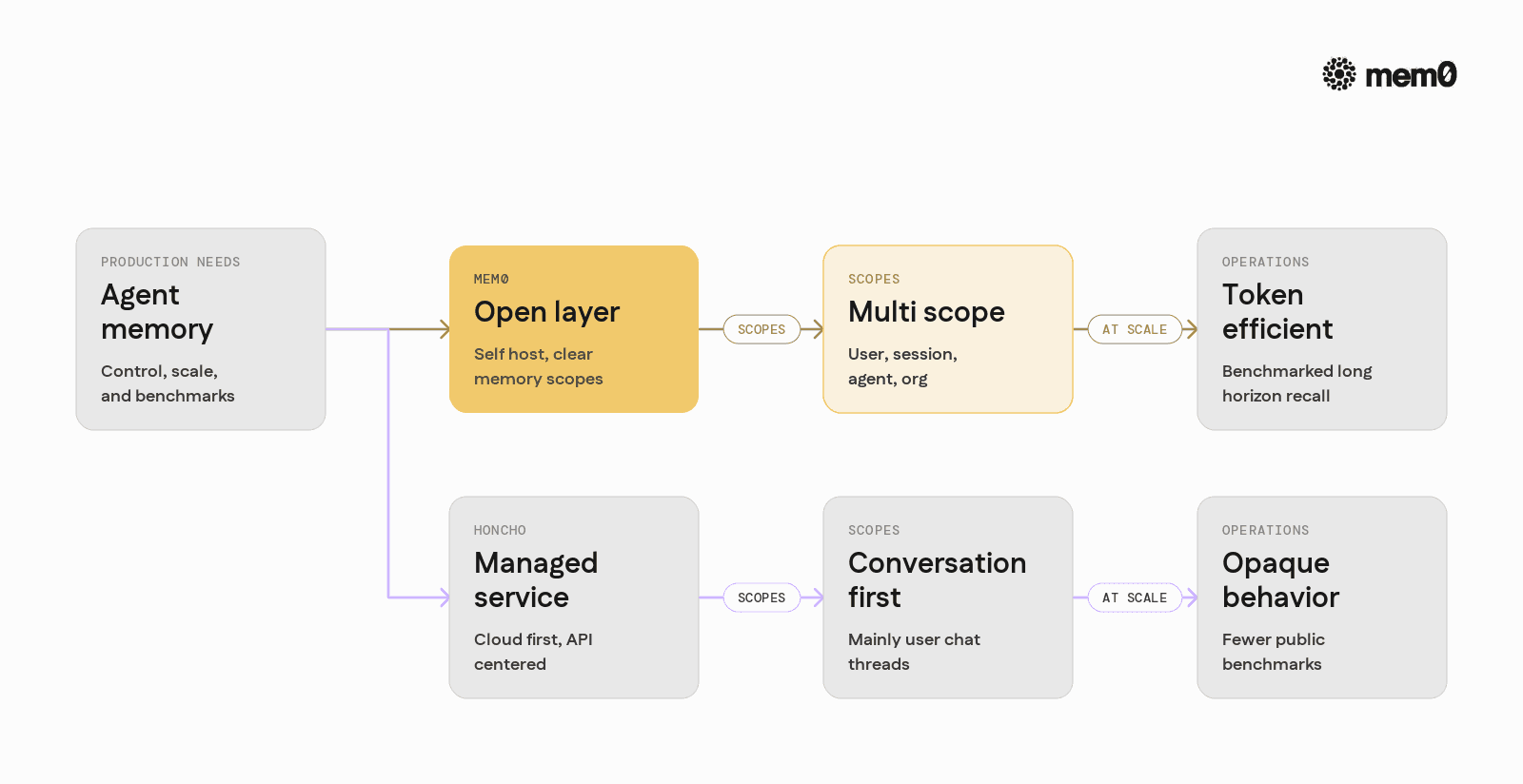
Dimension | Mem0 | Honcho |
|---|---|---|
Open source | Yes, full memory engine available on GitHub | Primarily a managed SaaS API |
Self-hosting | Supported, Docker and local installs | Not the primary path, cloud-first |
Memory scopes | Session, user, agent, organization | Mainly user / conversation oriented |
Token efficiency | Under ~7K tokens per retrieval on LongMemEval-S | Full details not publicly benchmarked |
Benchmarks | LongMemEval, LoCoMo, BEAM scores published | No comparable public long-memory benchmarks |
Integrations | LangChain, LlamaIndex, CrewAI, AutoGen, custom stacks | API oriented, custom integration |
Retrieval | Hybrid semantic, keyword, entity, and graph signals | Embedding-based retrieval with summarization |
Data residency control | Self-host or region-specific cloud | Cloud-centric, vendor controlled |
Primary focus | Dedicated memory layer for production agents | Managed memory service for agent builders |
This table simplifies some details, but it captures the practical considerations for engineers running agents under load, with compliance and cost constraints.
How Mem0 Solves the Core Memory Problem
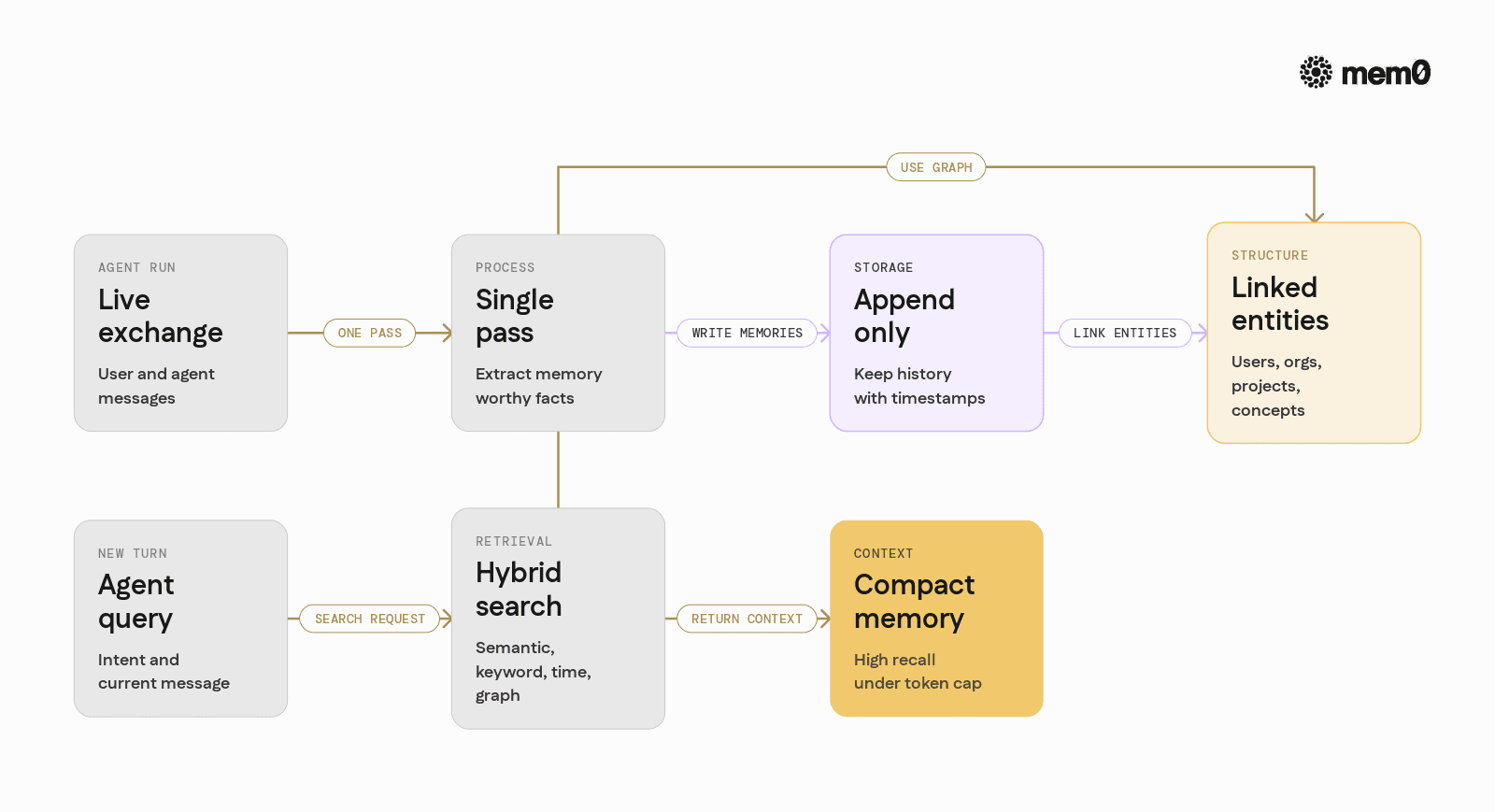
The core memory problem for agents is not “store and search text.” It is “maintain a consistent internal world model of the user and environment across time, at a cost that scales with production use.”
Mem0 attacks that problem with four central ideas.
1. Single-pass memory extraction
Instead of replaying entire histories or asking models to reread long logs, Mem0 processes each interaction once, extracts memory-worthy facts, and stores only those as structured memories. This avoids the pattern of repeatedly paying token costs to reprocess the same data.
2. ADD-only memory
Mem0 treats memory as append-only. It does not overwrite or erase historical items in place. Instead, it adds new observations that may supersede older ones.
This design keeps temporal reasoning intact. For example, if a user changes their address, both the old and the new address remain in memory with timestamps. The agent can reason about when the change happened, and the retrieval layer prioritizes the most relevant items.
3. Entity linking and graph structure
Mem0 links memory items across entities such as users, organizations, projects, and abstract concepts. A preference like “prefers dark mode” is tied to the user, and can also be associated with particular applications or workspaces when appropriate.
This entity-aware structure allows more targeted retrieval than simple chunk similarity, and it avoids polluting context with irrelevant but technically similar snippets.
4. Token-efficient hybrid retrieval
Mem0 retrieval uses a mix of:
Semantic similarity
Keyword matching
Entity relationships
Temporal signals
Results are combined and deduplicated, then compressed into a compact context. On LongMemEval-S, this stays under about 7K tokens per retrieval while retaining high recall. That pattern scales better than full-history injection or naive semantic search.
How Honcho Approaches Memory
Honcho focuses on making memory easy to bolt on. From public documentation, its approach can be summarized as:
Store conversations and state
Extract summaries or key facts
Retrieve relevant snippets for future prompts
This is conceptually similar to what many teams build internally when adding memory to agents for the first time. It is a major improvement over stateless agents, but several traits limit its effectiveness as workloads and horizon lengths grow.
Conversation-centric storage
Honcho emphasizes user conversations as the central source of truth. This is useful for chat-oriented applications, but it can make cross-agent and cross-organization reasoning harder to model. Mem0’s multi-scope model is more explicit about these boundaries.
Managed-first architecture
Honcho runs as a cloud service. Teams rely on the vendor to handle data storage, compliance, and scaling. This is convenient but less flexible for organizations that want strict data residency, air-gapped deployments, or tight control over infrastructure.
Limited public benchmarking
Without established benchmarks like LongMemEval or LoCoMo, it is harder for teams to reason about how Honcho behaves under extreme long-term recall scenarios or million-item memory stores. Mem0’s benchmark scores give more concrete expectations about behavior at scale.
Concrete Example: Integrating Mem0 in Python
The following example shows how an AI engineer can integrate Mem0 as a memory layer in a simple agent. It assumes use of openai for LLM calls, but the pattern is the same for other providers.
Installation
Basic Mem0 agent loop
This pattern demonstrates several Mem0 qualities that matter in production:
Memory tied to user, agent, and organization
Retrieval gives a concise context block instead of full transcript replay
Memory extraction happens in a single call to
mem0.add, no extra custom parsing
Replacing the backing LLM, changing frameworks, or migrating to a self-hosted Mem0 cluster does not change the memory logic itself.
Where Mem0 Stops
Mem0 focuses tightly on memory. It does not attempt to be an all-in-one platform that covers:
Orchestration across tools and services
Fine-grained routing or agentic planning
Full-featured RAG for arbitrary document collections
This constrained scope is deliberate. Mem0’s role is to maintain persistent, accurate memory that any agent framework can consume. For complex tool orchestration, dedicated agent frameworks handle planning and execution.
Honcho, by contrast, positions itself closer to a holistic agent infrastructure with baked-in memory. This can be helpful for small projects but can also lock teams into a specific orchestration model.
Production Considerations: Scaling and Operations
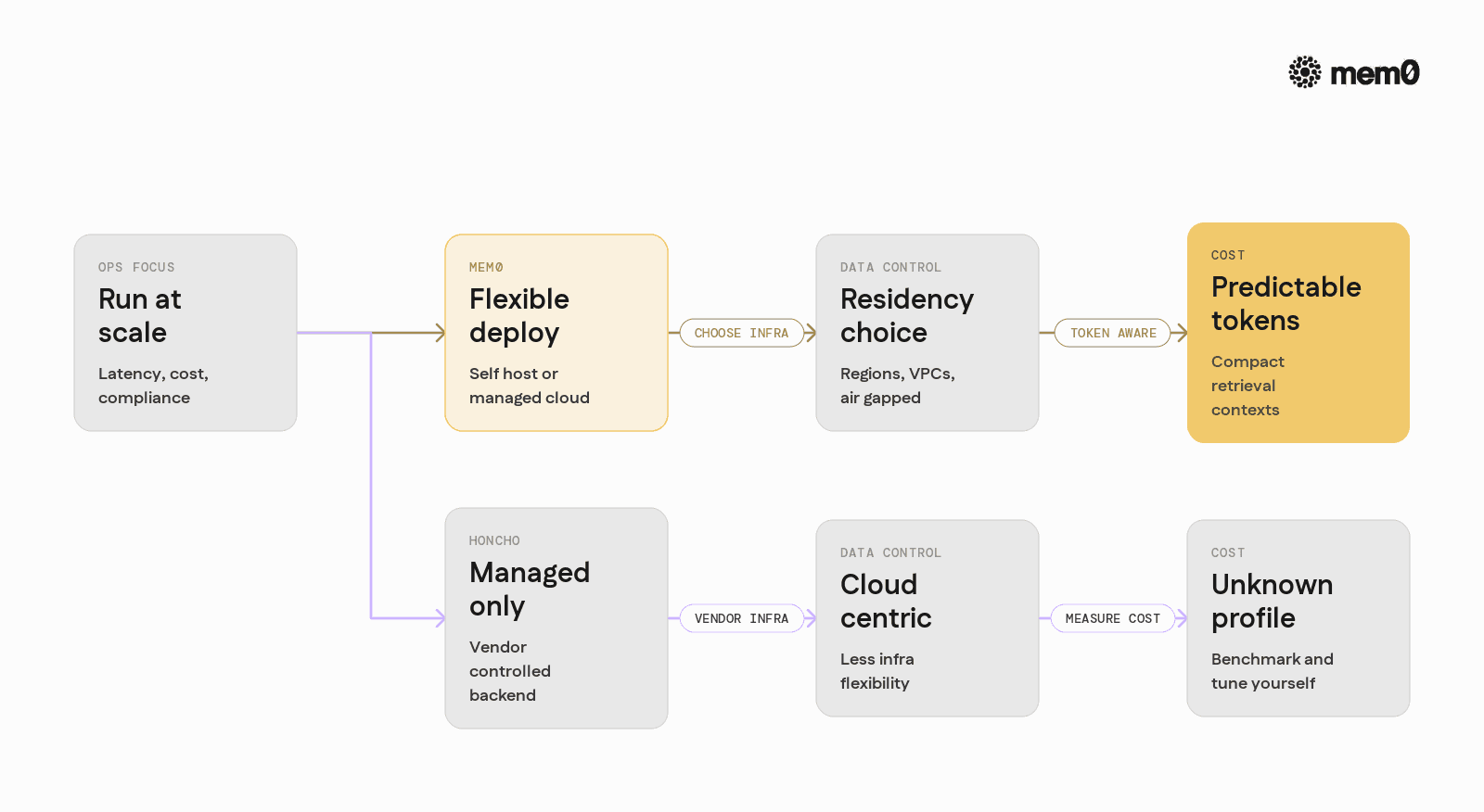
For AI engineers responsible for uptime and cost, several operational questions drive the decision between Mem0 and Honcho.
Data control and compliance
Mem0 supports:
Self-hosted deployments using Docker and Kubernetes
Local-first setups for development and on-device experiments
Managed cloud with SOC 2 and HIPAA coverage
Self-hosting increases control over:
Data residency, for example keeping memory in a specific region
Network boundaries, including private VPCs or air-gapped setups
Custom logging, audit, and retention policies
Honcho as a managed service reduces operational burden but gives less control over these aspects.
Cost predictability
Token-efficient retrieval is key for cost control. If memory retrieval injects tens of thousands of tokens into every call, LLM spend grows with memory size. Mem0’s algorithm keeps context compact while preserving recall, which scales better when agents run at production traffic.
Honcho’s cost profile depends on its internal retrieval and summarization strategies. Without detailed public metrics, teams often need to benchmark on their own data to understand long-horizon costs.
Framework compatibility
Mem0 does not prescribe a specific agent framework. It integrates through clean APIs and SDKs, so teams can:
Start with LangChain or LlamaIndex
Move to a homegrown orchestration layer
Mix and match tools and frameworks over time
Honcho’s value proposition is tightly tied to its own API. This is fine when the agent stack is small, but may introduce friction when integrating existing internal systems.
Limitations of These Patterns
Both Mem0 and Honcho represent a specific pattern for agent memory. That pattern has several inherent limits, regardless of implementation.
Memory is not full observability
Persistent memory is not a substitute for logging, tracing, or metrics. Trying to put every interaction detail into memory leads to noise, slower retrieval, and higher costs. Engineers still need proper observability infrastructure alongside memory.
Long-horizon memory has diminishing returns
Beyond a certain horizon, very old context rarely influences present behavior. Even highly accurate algorithms will retrieve data that an agent rarely needs. The challenge becomes identifying what is truly memory-worthy. Neither Mem0 nor Honcho can decide business-specific semantics on their own, so application logic and domain signals still matter.
Retrieval quality is workload-specific
Benchmarks like LongMemEval and LoCoMo provide helpful anchors, but real workloads vary. For some applications, semantic similarity matters more. For others, strict temporal logic or structured attributes dominate. Both Mem0 and Honcho need tuning and evaluation on real traffic to reach production quality.
Multi-tenant complexity remains
Even with clear memory scopes, multi-tenant applications must handle ownership, isolation, and access control. The memory layer can provide scopes, but permissioning, cross-tenant analytics, and migration duties still live in application code and infrastructure.
Frequently Asked Questions
When should AI engineers choose Mem0 over Honcho?
Mem0 fits best when the priority is production-grade, persistent memory with clear scopes across users, sessions, agents, and organizations. It is also ideal when teams need self-hosting, explicit data control, and transparent long-memory benchmarks for evaluation.
How does Mem0’s token-efficient retrieval help in practice?
Mem0’s retrieval design keeps context sizes modest while preserving high recall on long-memory benchmarks. In practice, this means LLM calls stay cheaper, latency remains stable as memory grows, and agents avoid drowning in irrelevant history.
Can Mem0 and Honcho be used together in the same stack?
In principle, yes. An application could use Mem0 as the primary long-term memory layer and call Honcho for specific workflows that rely on its managed services. In practice, most teams choose one primary memory platform to reduce complexity and avoid duplicating storage.
How difficult is it to migrate from Honcho to Mem0?
Migration usually involves exporting stored memories or conversation transcripts and importing them into Mem0 with appropriate scopes. Since Mem0 integrates through standard SDKs and APIs, most work sits in transforming data and updating retrieval calls in the agent logic.
Does Mem0 support local development without calling a cloud service?
Yes. Mem0 can run locally via Docker or as part of a self-hosted setup, which is useful for development, on-device agents, or environments with strict network rules. Developers can test full memory behavior without sending data to the public cloud.
How does Mem0 handle different teams or business units within one company?
Mem0 uses organization and agent scopes to separate and structure memory. A company can isolate memory by organization, then subdivide by specific agents or products, which keeps recall focused and simplifies permissioning in multi-team deployments.
Further Reading
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

