



Overview of the production memory problem
AI engineers building production agents run into the same bottleneck: LLMs forget everything that does not fit into the current context window. Once agents run for days, across users and workflows, the cost of naïvely replaying history through the prompt becomes unsustainable.
Memory platforms try to solve this by extracting, organizing, and retrieving the right pieces of information at the right time. The details matter. How memory is stored, which signals are used to retrieve it, and how much context is shipped to the model together turn into direct effects on latency, cost, and agent quality.
Mem0 and Zep both address this gap, but with different architectures and priorities. Mem0 focuses on token‑efficient, long‑horizon agent memory for production traffic. Zep focuses on graph‑centric knowledge and temporal relations. Understanding that difference helps clarify which system fits which type of agent.
High level comparison of Mem0 and Zep
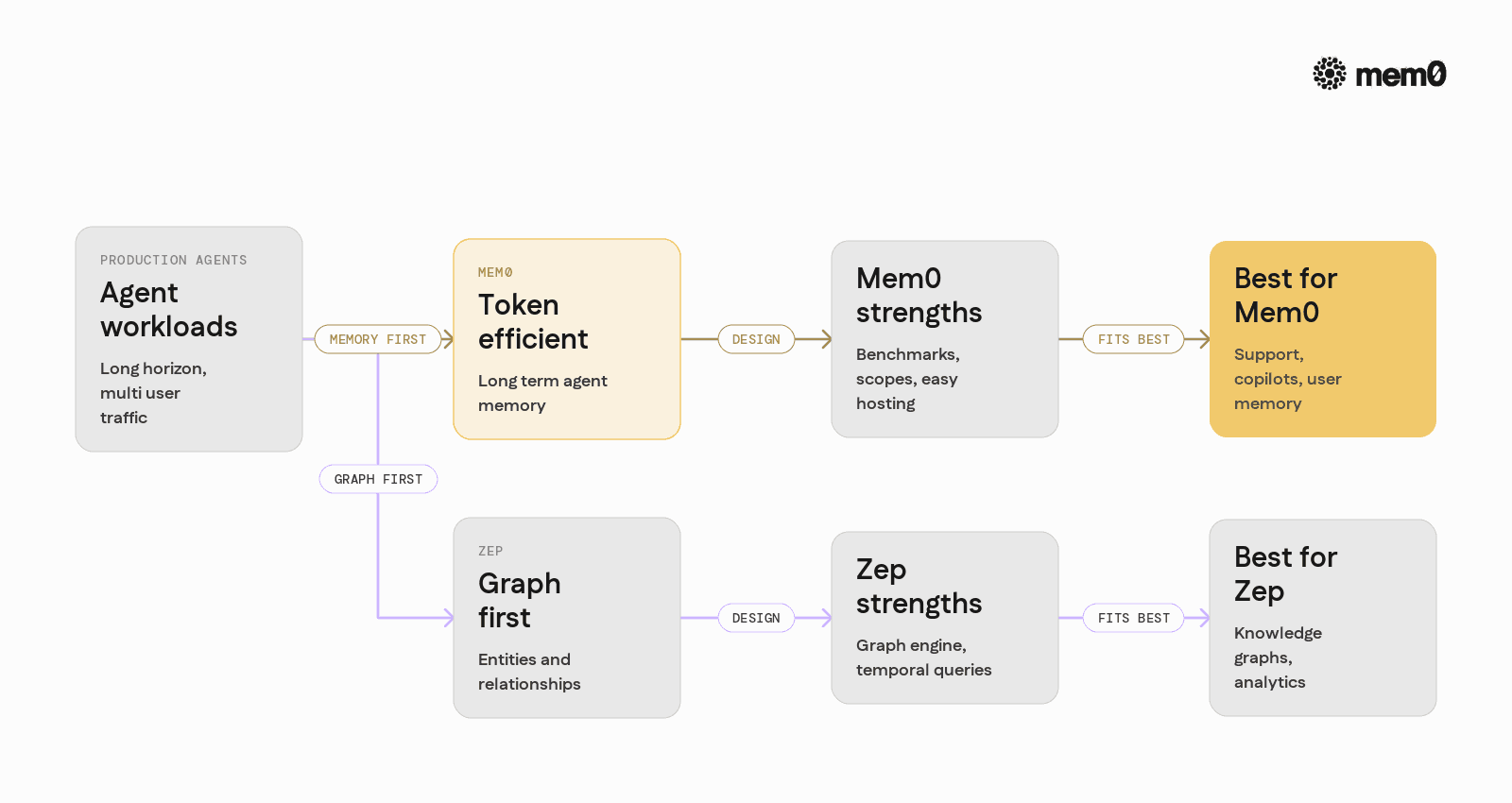
Both tools offer managed cloud, developer‑friendly APIs, and language‑model centric abstractions. The contrast shows up in what they optimize first.
Mem0 is designed as a service‑agnostic memory layer that works alongside any LLM provider, orchestrator, or agent framework. It targets long‑term agent memory with published benchmarks like LongMemEval, LoCoMo, and BEAM, plus clear controls over scopes such as session, user, agent, and organization.
Zep has a strong emphasis on graph‑first memory through its Graphiti engine. It shines when engineers want to model entities and relationships explicitly in a graph database and treat conversational memory as one data source among many.
The table below summarizes the most visible differences for production agents.
Mem0 vs Zep feature comparison
Feature | Mem0 | Zep |
|---|---|---|
Open source | ✅ Active OSS memory layer | ✅ Community Edition existed, now deprecated |
Managed cloud | ✅ Production API | ✅ Managed cloud |
Free tier | ✅ Free managed tier, self‑host at no cost | ✅ Free tier with limited episode credits |
Pricing (entry) | From ~$19 / month | From ~$125 / month |
Self‑hosting | ✅ Simple Docker deployment, Python / JS SDKs | ⚠️ CE deprecated, self‑hosting requires Graphiti plus external graph database |
LongMemEval | 94.4 | 71.2 (GPT‑4o) |
LoCoMo | 92.5 | ~80 range reported |
BEAM 1M / 10M | 64.1 / 48.6 | Not published |
Agent Harness | Integrated in OpenClaw and Hermes‑style agents | Not available as standard harness |
Memory scopes | Session, user, agent, organization | Session, user |
Local / MCP support | ✅ Local, MCP compatible | ✅ Local options available |
Service agnostic | ✅ Works with any LLM, any framework | Tighter coupling to specific stacks |
Installation time | ~60 seconds to first write | Often >20 minutes for full graph setup |
Framework support | LangChain, LlamaIndex, CrewAI, AutoGen, direct HTTP / SDK, and more | Native LangChain and LangGraph, plus HTTP APIs |
The core tradeoff is straightforward. Mem0 optimizes for accurate, token‑efficient recall across many users and long histories. Zep optimizes for graph‑native control of entities and relationships. For production agents that mainly need to remember user context, preferences, and task state, the first class of problems often matters more.
How Mem0’s token efficient memory works
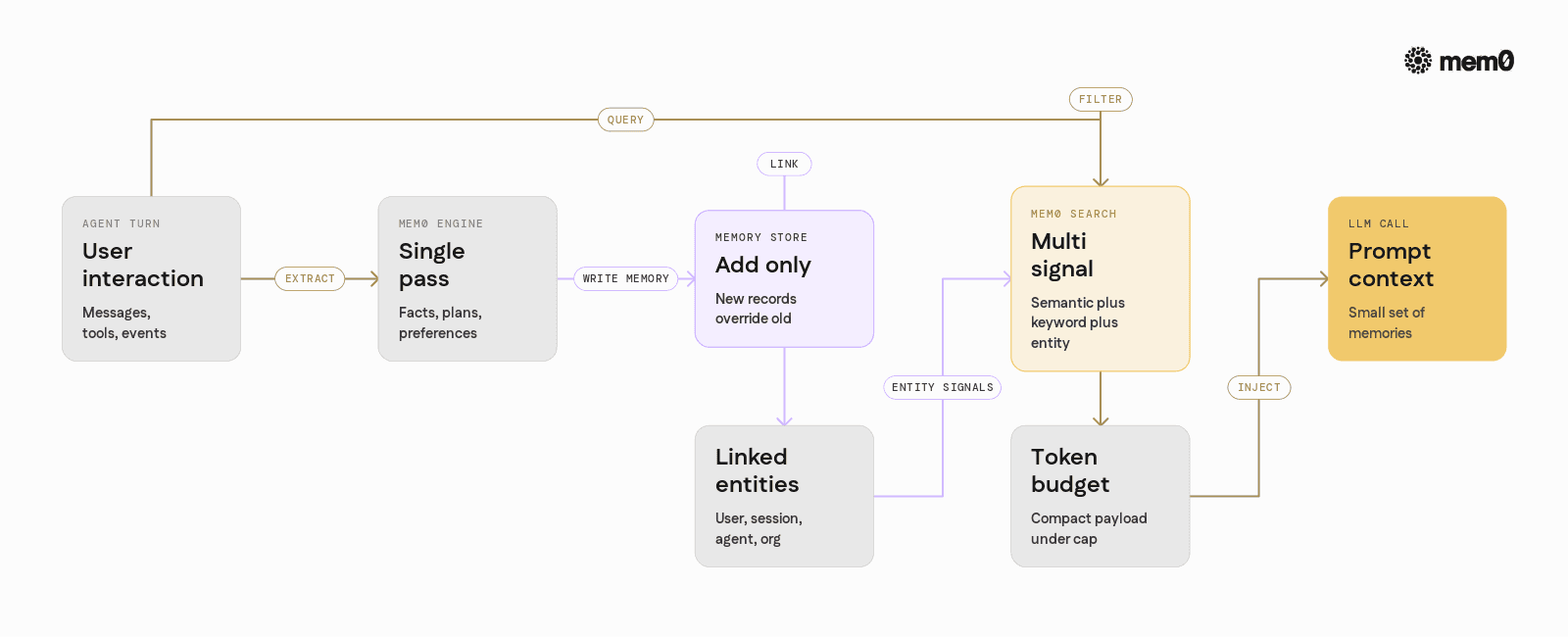
Most memory systems start by logging entire conversations, then derive embeddings and additional structure. Retrieval often selects chunks of that history based on vector similarity and sends them straight back into the prompt. This is simple, but when conversations grow large, the token count per call explodes.
Mem0 takes a different path. It implements a token efficient memory algorithm with a few key ideas:
Single pass memory extraction
Instead of storing raw conversation tokens as the primary artifact, Mem0 runs extraction that produces structured memories, such as facts, preferences, plans, and corrections. This happens in one pass per interaction and produces compact records.Add‑only historical store
Memories are stored as append‑only by default. When a user preference changes, a new memory is added that explicitly overrides the previous one. This avoids destructive updates, keeps history intact, and simplifies reasoning about temporal changes.Entity linking and multi‑signal retrieval
Memories are linked to entities such as users, projects, or agents. Retrieval combines semantic similarity, keyword matching, and entity signals. This allows the system to fetch the right few memories while ignoring the rest of the log.Token budget aware retrieval
Mem0 aims to keep average retrieval payloads under about seven thousand tokens on long horizon benchmarks. Instead of returning full conversations, it returns the smallest set of memories that can answer the current query or inform the next tool call.
On benchmarks like LongMemEval‑S, full context approaches that stuff large parts of the conversation can climb to around one hundred fifteen thousand tokens per retrieval. Mem0 achieves higher recall with a fraction of that footprint. For production traffic this often translates directly into lower cost, faster responses, and more predictable behavior.
Zep’s graph first memory model
Zep is better understood as a graph‑centric memory infrastructure. Its Graphiti engine treats entities and relations as first class, backed by a graph database such as Neo4j or similar systems. Conversational memory is integrated into that graph, which also hosts external knowledge.
In this model, engineers define nodes representing people, resources, documents, tools, and events. Edges encode relationships and timestamps. Queries spanning multiple modalities, such as "show all users who mentioned a bug related to feature X after release Y", become straightforward graph traversals.
This suits applications where knowledge management and analytics matter as much as conversational recall. For instance, storing product telemetry, issue reports, and support conversations in a unified graph can enable rich analysis outside of the LLM runtime.
The cost of this flexibility is more operational complexity. Running a graph database, a memory extraction pipeline, and an LLM stack together is heavier than a single purpose memory service. For many agents that mainly need consistent user memory and task state, that extra complexity can be overkill.
Where Mem0 fits better for production agents
Mem0 aligns with a common profile for production agent workloads:
High volume, multi‑user agents (support bots, coding copilots, account managers)
Need to recall user details across weeks or months
Need to track task state that spans multiple sessions and workflows
Need to run inside predictable latency and cost budgets
Mem0 exposes clear scopes such as session, user, agent, and org. That lets engineers express intent precisely. A debugging assistant can remember per‑user preferences. A team knowledge agent can share certain memories across an organization, while keeping private data isolated.
Since Mem0 is service agnostic, it can sit behind any orchestrator. It can back a LangChain agent, a custom FastAPI service, or an MCP tool running locally. The focus on benchmarks, such as LongMemEval, LoCoMo, and BEAM, means there are quantitative references for how memory behaves at scale.
For engineers, this often removes a whole category of decisions. Instead of hand crafting retrieval pipelines, they can delegate long‑term memory to a system optimized for that job, then tune scopes and indexing settings as needed.
Where Zep still makes sense
There are valid cases where Zep is a better fit.
If the application is graph native from the start, for example:
A research agent that needs to build and traverse a large knowledge graph of papers and citations
An enterprise knowledge platform that centralizes documents, metrics, and events as nodes and edges
then a graph first memory system lines up with the core domain.
In those situations, conversational memory is only one channel for ingesting data into the graph. The LLM may query the graph directly or act on top of it with specialized tools. The memory platform becomes part of a broader knowledge graph architecture, not just a way to remember user chats.
The tradeoff is that long‑term recall benchmarks are less of a focus. Published numbers for tasks like LoCoMo or BEAM are limited or absent, so tuning memory behavior for long horizon agents usually involves trial and error.
Practical Python integration with Mem0
To make the comparison concrete, the snippet below shows how Mem0 can be integrated into a simple Python agent that runs against OpenAI or any other LLM. The agent stores user memories after each turn and retrieves them before each reply, scoped by user and agent.
This example shows a minimal pattern:
Mem0 handles extraction and retrieval, not the application
The agent code only needs to call
addandsearchwith the right scopesMemory size can grow large, while the prompt stays within a manageable token budget
Porting similar logic to a framework such as LangChain or LlamaIndex is straightforward by using Mem0’s dedicated integrations.
Production use cases where Mem0 vs Zep diverge
Several practical scenarios highlight where the two systems differ.
Customer support agents
A support agent must remember user history across tickets, channels, and time. Mem0 fits naturally by storing per‑user and per‑org memories from each interaction and retrieving them efficiently before each response. Zep can also store this data, but configuring graphs and maintaining a database may not add much value for this narrow problem.Coding copilots and internal dev tools
Copilots benefit from remembering repository context, developer preferences, and ongoing tasks. Mem0 can attach memories to agents and users without requiring a full knowledge graph. Zep becomes valuable if the team also wants to run graph analytics on code structure or dependencies.Multi‑agent workflows
For complex systems where multiple agents cooperate, Mem0’s agent scope enables shared memory across agents while preserving isolation between organizations. Engineers can model each agent as a participant in the same memory layer. In a graph first system, similar patterns are possible but often require careful schema design.
Limitations of each approach
The patterns behind both tools have boundaries.
Mem0’s token efficient memory algorithm is optimized for conversational and agent memory, not for arbitrary analytics. It is not a general purpose data warehouse or OLAP engine. It stores structured memories and metadata, but it is not intended for complex joins or global reporting over billions of records.
Mem0 also depends on meaningful signals from the application. If engineers never send important events, such as critical tool results or user corrections, then those events cannot be recalled later. Memory quality still reflects input quality.
Zep’s graph first model, in contrast, can express rich relationships and queries, but at the cost of operational overhead. Maintaining a graph database at scale requires capacity planning, backup processes, and specialized observability. It is also easy to design graphs that are too complex for typical LLM calls to use effectively.
For both systems, there is still inherent uncertainty from the LLM itself. Even with perfect recall, models can misinterpret or ignore retrieved memories. No memory platform can fully remove this stochastic element.
Frequently Asked Questions
How does Mem0’s algorithm work in practice?
Mem0 extracts structured memories in a single pass from interactions, stores them as add‑only records, and links them to entities such as users and agents. Retrieval combines semantic, keyword, and entity signals to return compact, high value context under a controlled token budget, often below seven thousand tokens per call on long horizon tasks. This contrasts with full history approaches that can push token counts past one hundred thousand.
Do Mem0 and Zep both offer free options?
Mem0 provides a free tier in its managed cloud along with an open source package that can be self‑hosted at no cost. Zep formerly offered a community edition that was self‑hostable and is now deprecated, while Zep Cloud retains a free tier with limited credits alongside paid plans. Engineers should check each project’s documentation for current limits and pricing.
Can both Mem0 and Zep be self‑hosted?
Mem0 can be self‑hosted easily through Docker and simple configuration, and its Python and JavaScript SDKs work identically against self‑hosted or managed endpoints. Zep’s historical community edition allowed direct self‑hosting, but with its deprecation, self‑hosting usually involves running Graphiti together with a compatible graph database. This is more complex operationally than running a single memory service.
How can an engineer get started with Mem0 for an existing agent?
The usual path is to create a Mem0 account or deploy the open source server locally, then integrate the SDK into the agent’s middleware layer. Engineers typically add calls to add after each important event and to search before each LLM call, scoped by user, session, agent, or organization. Framework specific guides exist for LangChain, LlamaIndex, CrewAI, AutoGen, and custom orchestrators.
Further Reading
Mem0 is an intelligent, open-source memory layer designed for LLMs and AI agents to provide long-term, personalized, and context-aware interactions across sessions.
Get your free API Key here: app.mem0.ai or self-host mem0 from our open source github repository.
GET TLDR from:

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

Summarize
Website/Footer

